Introduction: Processing thousands or millions of items through LLMs requires different patterns than single-request applications. Naive sequential processing is too slow, while uncontrolled parallelism hits rate limits and wastes money on retries. This guide covers production batch processing patterns: chunking strategies, parallel execution with rate limiting, progress tracking, checkpoint/resume for long jobs, cost estimation, and handling partial failures gracefully. These patterns apply whether you’re processing documents, generating embeddings, or running classification at scale.
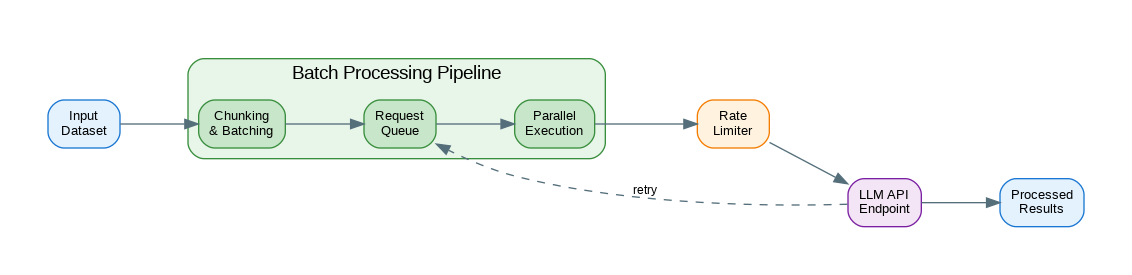
Basic Batch Processing
import asyncio
from openai import AsyncOpenAI
from typing import TypeVar, Callable, Awaitable
from dataclasses import dataclass
T = TypeVar('T')
R = TypeVar('R')
client = AsyncOpenAI()
@dataclass
class BatchResult:
successful: list[tuple[int, any]]
failed: list[tuple[int, Exception]]
@property
def success_rate(self) -> float:
total = len(self.successful) + len(self.failed)
return len(self.successful) / total if total > 0 else 0
async def process_batch(
items: list[T],
processor: Callable[[T], Awaitable[R]],
max_concurrent: int = 10
) -> BatchResult:
"""Process items with controlled concurrency."""
semaphore = asyncio.Semaphore(max_concurrent)
successful = []
failed = []
async def process_one(idx: int, item: T):
async with semaphore:
try:
result = await processor(item)
successful.append((idx, result))
except Exception as e:
failed.append((idx, e))
tasks = [process_one(i, item) for i, item in enumerate(items)]
await asyncio.gather(*tasks)
return BatchResult(successful=successful, failed=failed)
# Example: Classify documents
async def classify_document(text: str) -> str:
response = await client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Classify the document into: tech, business, science, other"},
{"role": "user", "content": text[:2000]}
]
)
return response.choices[0].message.content
# Usage
documents = ["Document 1...", "Document 2...", ...] # 1000 documents
result = await process_batch(documents, classify_document, max_concurrent=20)
print(f"Success rate: {result.success_rate:.1%}")
print(f"Failed: {len(result.failed)}")Rate-Limited Batch Processor
import time
from collections import deque
class RateLimitedBatchProcessor:
"""Batch processor with token bucket rate limiting."""
def __init__(
self,
requests_per_minute: int = 500,
tokens_per_minute: int = 150000,
max_concurrent: int = 50
):
self.rpm = requests_per_minute
self.tpm = tokens_per_minute
self.max_concurrent = max_concurrent
self.request_times: deque = deque()
self.token_usage: deque = deque()
self.semaphore = asyncio.Semaphore(max_concurrent)
self.lock = asyncio.Lock()
async def _wait_for_capacity(self, estimated_tokens: int):
"""Wait until we have capacity for the request."""
while True:
async with self.lock:
now = time.time()
minute_ago = now - 60
# Clean old entries
while self.request_times and self.request_times[0] < minute_ago:
self.request_times.popleft()
while self.token_usage and self.token_usage[0][0] < minute_ago:
self.token_usage.popleft()
# Check capacity
current_requests = len(self.request_times)
current_tokens = sum(t[1] for t in self.token_usage)
if current_requests < self.rpm and current_tokens + estimated_tokens < self.tpm:
self.request_times.append(now)
self.token_usage.append((now, estimated_tokens))
return
# Wait and retry
await asyncio.sleep(0.1)
async def process(
self,
items: list[T],
processor: Callable[[T], Awaitable[R]],
estimate_tokens: Callable[[T], int] = lambda x: 500
) -> BatchResult:
"""Process items with rate limiting."""
successful = []
failed = []
async def process_one(idx: int, item: T):
async with self.semaphore:
tokens = estimate_tokens(item)
await self._wait_for_capacity(tokens)
try:
result = await processor(item)
successful.append((idx, result))
except Exception as e:
failed.append((idx, e))
tasks = [process_one(i, item) for i, item in enumerate(items)]
await asyncio.gather(*tasks)
return BatchResult(successful=successful, failed=failed)
# Usage
processor = RateLimitedBatchProcessor(
requests_per_minute=500,
tokens_per_minute=150000,
max_concurrent=50
)
def estimate_tokens(text: str) -> int:
return len(text) // 4 + 100 # Rough estimate
result = await processor.process(
documents,
classify_document,
estimate_tokens=estimate_tokens
)Checkpoint and Resume
import json
from pathlib import Path
from dataclasses import dataclass, asdict
from typing import Optional
@dataclass
class BatchCheckpoint:
job_id: str
total_items: int
processed_indices: set[int]
results: dict[int, any]
errors: dict[int, str]
def save(self, path: Path):
data = {
"job_id": self.job_id,
"total_items": self.total_items,
"processed_indices": list(self.processed_indices),
"results": self.results,
"errors": self.errors
}
path.write_text(json.dumps(data))
@classmethod
def load(cls, path: Path) -> "BatchCheckpoint":
data = json.loads(path.read_text())
return cls(
job_id=data["job_id"],
total_items=data["total_items"],
processed_indices=set(data["processed_indices"]),
results=data["results"],
errors=data["errors"]
)
class ResumableBatchProcessor:
"""Batch processor with checkpoint/resume support."""
def __init__(
self,
job_id: str,
checkpoint_dir: Path = Path("./checkpoints"),
checkpoint_interval: int = 100
):
self.job_id = job_id
self.checkpoint_dir = checkpoint_dir
self.checkpoint_interval = checkpoint_interval
self.checkpoint_dir.mkdir(exist_ok=True)
self.checkpoint_path = checkpoint_dir / f"{job_id}.json"
async def process(
self,
items: list[T],
processor: Callable[[T], Awaitable[R]],
max_concurrent: int = 20
) -> BatchCheckpoint:
"""Process with automatic checkpointing."""
# Load or create checkpoint
if self.checkpoint_path.exists():
checkpoint = BatchCheckpoint.load(self.checkpoint_path)
print(f"Resuming from checkpoint: {len(checkpoint.processed_indices)}/{checkpoint.total_items}")
else:
checkpoint = BatchCheckpoint(
job_id=self.job_id,
total_items=len(items),
processed_indices=set(),
results={},
errors={}
)
# Find unprocessed items
pending = [
(i, item) for i, item in enumerate(items)
if i not in checkpoint.processed_indices
]
semaphore = asyncio.Semaphore(max_concurrent)
lock = asyncio.Lock()
processed_count = 0
async def process_one(idx: int, item: T):
nonlocal processed_count
async with semaphore:
try:
result = await processor(item)
async with lock:
checkpoint.results[idx] = result
checkpoint.processed_indices.add(idx)
processed_count += 1
# Checkpoint periodically
if processed_count % self.checkpoint_interval == 0:
checkpoint.save(self.checkpoint_path)
print(f"Checkpoint saved: {len(checkpoint.processed_indices)}/{checkpoint.total_items}")
except Exception as e:
async with lock:
checkpoint.errors[idx] = str(e)
checkpoint.processed_indices.add(idx)
tasks = [process_one(i, item) for i, item in pending]
await asyncio.gather(*tasks)
# Final checkpoint
checkpoint.save(self.checkpoint_path)
return checkpoint
# Usage
processor = ResumableBatchProcessor(
job_id="classify_docs_2024",
checkpoint_interval=50
)
checkpoint = await processor.process(documents, classify_document)
print(f"Completed: {len(checkpoint.results)}")
print(f"Errors: {len(checkpoint.errors)}")Cost Estimation and Tracking
from dataclasses import dataclass
@dataclass
class ModelPricing:
input_per_1k: float
output_per_1k: float
PRICING = {
"gpt-4o": ModelPricing(0.0025, 0.01),
"gpt-4o-mini": ModelPricing(0.00015, 0.0006),
"gpt-4-turbo": ModelPricing(0.01, 0.03),
"claude-3-5-sonnet": ModelPricing(0.003, 0.015),
}
class CostTracker:
"""Track and estimate LLM costs."""
def __init__(self, model: str):
self.model = model
self.pricing = PRICING.get(model, ModelPricing(0.01, 0.03))
self.total_input_tokens = 0
self.total_output_tokens = 0
self.request_count = 0
def estimate_batch_cost(
self,
items: list[str],
avg_output_tokens: int = 100
) -> float:
"""Estimate cost before running."""
total_input = sum(len(item) // 4 for item in items)
total_output = len(items) * avg_output_tokens
input_cost = (total_input / 1000) * self.pricing.input_per_1k
output_cost = (total_output / 1000) * self.pricing.output_per_1k
return input_cost + output_cost
def record_usage(self, input_tokens: int, output_tokens: int):
"""Record actual usage."""
self.total_input_tokens += input_tokens
self.total_output_tokens += output_tokens
self.request_count += 1
@property
def total_cost(self) -> float:
input_cost = (self.total_input_tokens / 1000) * self.pricing.input_per_1k
output_cost = (self.total_output_tokens / 1000) * self.pricing.output_per_1k
return input_cost + output_cost
def summary(self) -> str:
return f"""
Cost Summary:
Requests: {self.request_count:,}
Input tokens: {self.total_input_tokens:,}
Output tokens: {self.total_output_tokens:,}
Total cost: ${self.total_cost:.4f}
Avg cost/request: ${self.total_cost / max(self.request_count, 1):.6f}
"""
# Usage with batch processor
tracker = CostTracker("gpt-4o-mini")
# Estimate before running
estimated = tracker.estimate_batch_cost(documents)
print(f"Estimated cost: ${estimated:.2f}")
# Track during processing
async def classify_with_tracking(text: str) -> str:
response = await client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Classify: tech, business, science, other"},
{"role": "user", "content": text[:2000]}
]
)
tracker.record_usage(
response.usage.prompt_tokens,
response.usage.completion_tokens
)
return response.choices[0].message.content
result = await process_batch(documents, classify_with_tracking)
print(tracker.summary())OpenAI Batch API
import json
from openai import OpenAI
client = OpenAI()
def create_batch_file(items: list[dict], output_path: str) -> str:
"""Create JSONL file for batch API."""
with open(output_path, 'w') as f:
for i, item in enumerate(items):
request = {
"custom_id": f"request-{i}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": item["messages"],
"max_tokens": 1000
}
}
f.write(json.dumps(request) + "\n")
return output_path
def submit_batch(file_path: str) -> str:
"""Submit batch job to OpenAI."""
# Upload file
with open(file_path, 'rb') as f:
file = client.files.create(file=f, purpose="batch")
# Create batch
batch = client.batches.create(
input_file_id=file.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
return batch.id
def check_batch_status(batch_id: str) -> dict:
"""Check batch job status."""
batch = client.batches.retrieve(batch_id)
return {
"status": batch.status,
"completed": batch.request_counts.completed,
"failed": batch.request_counts.failed,
"total": batch.request_counts.total
}
def get_batch_results(batch_id: str) -> list[dict]:
"""Download batch results."""
batch = client.batches.retrieve(batch_id)
if batch.status != "completed":
raise ValueError(f"Batch not complete: {batch.status}")
# Download output file
content = client.files.content(batch.output_file_id)
results = []
for line in content.text.split("\n"):
if line:
results.append(json.loads(line))
return results
# Usage - 50% cheaper than real-time API
items = [
{"messages": [{"role": "user", "content": doc}]}
for doc in documents
]
# Create and submit
file_path = create_batch_file(items, "batch_input.jsonl")
batch_id = submit_batch(file_path)
print(f"Batch submitted: {batch_id}")
# Poll for completion
import time
while True:
status = check_batch_status(batch_id)
print(f"Status: {status['status']} - {status['completed']}/{status['total']}")
if status["status"] in ("completed", "failed", "expired"):
break
time.sleep(60)
# Get results
results = get_batch_results(batch_id)References
- OpenAI Batch API: https://platform.openai.com/docs/guides/batch
- Anthropic Message Batches: https://docs.anthropic.com/en/docs/build-with-claude/message-batches
- asyncio Documentation: https://docs.python.org/3/library/asyncio.html
Conclusion
Batch processing LLMs at scale requires careful orchestration of concurrency, rate limiting, and error handling. Start with controlled parallelism using semaphores to avoid overwhelming APIs. Implement token bucket rate limiting to stay within provider limits. Add checkpoint/resume for long-running jobs so failures don’t lose progress. Track costs throughout to avoid surprises. For large batches, consider OpenAI’s Batch API which offers 50% cost savings for non-urgent workloads. The patterns here scale from hundreds to millions of items—the key is building robust infrastructure that handles failures gracefully and provides visibility into progress. Always estimate costs before running large batches, and start with a small sample to validate your processing logic before committing to the full dataset.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.