Introduction: Vector embeddings are the foundation of modern AI applications—from semantic search to RAG systems to recommendation engines. They transform text, images, and other data into dense numerical representations that capture semantic meaning, enabling machines to understand similarity and relationships in ways that traditional keyword matching never could. This guide provides a deep dive into embeddings: how they work, which models to use, and practical code for building production systems.
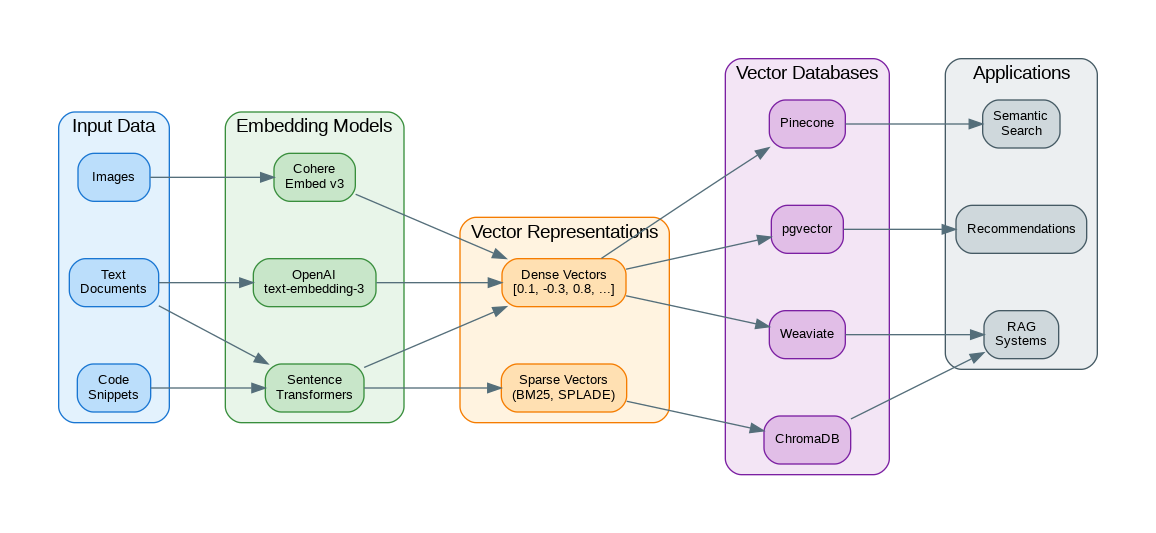
Understanding Vector Embeddings
An embedding is a vector (array of numbers) that represents data in a high-dimensional space where similar items are positioned close together. A sentence about “machine learning” will have a vector similar to one about “artificial intelligence” but distant from one about “cooking recipes.”
import numpy as np
from openai import OpenAI
client = OpenAI()
def get_embedding(text: str, model: str = "text-embedding-3-small") -> list[float]:
"""Get embedding vector for text using OpenAI."""
response = client.embeddings.create(
input=text,
model=model
)
return response.data[0].embedding
# Example: Compare semantic similarity
text1 = "Machine learning is transforming industries"
text2 = "AI is revolutionizing business operations"
text3 = "The weather is sunny today"
emb1 = np.array(get_embedding(text1))
emb2 = np.array(get_embedding(text2))
emb3 = np.array(get_embedding(text3))
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
print(f"ML vs AI: {cosine_similarity(emb1, emb2):.4f}") # ~0.85 (similar)
print(f"ML vs Weather: {cosine_similarity(emb1, emb3):.4f}") # ~0.20 (different)Choosing an Embedding Model
| Model | Dimensions | Max Tokens | Best For | Cost |
|---|---|---|---|---|
| text-embedding-3-small | 1536 | 8191 | General purpose, cost-effective | $0.02/1M tokens |
| text-embedding-3-large | 3072 | 8191 | Maximum accuracy | $0.13/1M tokens |
| all-MiniLM-L6-v2 | 384 | 256 | Fast, local, free | Free (local) |
| Cohere embed-v3 | 1024 | 512 | Multilingual | $0.10/1M tokens |
| voyage-large-2 | 1536 | 16000 | Long documents | $0.12/1M tokens |
Local Embeddings with Sentence Transformers
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a local model (downloads once, runs offline)
model = SentenceTransformer('all-MiniLM-L6-v2')
# Single text embedding
text = "Vector databases enable semantic search"
embedding = model.encode(text)
print(f"Embedding shape: {embedding.shape}") # (384,)
# Batch embedding (much faster)
documents = [
"Python is a programming language",
"JavaScript runs in browsers",
"Machine learning uses neural networks",
"Databases store structured data",
"APIs enable system integration"
]
embeddings = model.encode(documents, show_progress_bar=True)
print(f"Batch shape: {embeddings.shape}") # (5, 384)
# Find most similar documents to a query
query = "How do I store data?"
query_embedding = model.encode(query)
# Calculate similarities
similarities = np.dot(embeddings, query_embedding) / (
np.linalg.norm(embeddings, axis=1) * np.linalg.norm(query_embedding)
)
# Rank by similarity
ranked_indices = np.argsort(similarities)[::-1]
for idx in ranked_indices[:3]:
print(f"{similarities[idx]:.4f}: {documents[idx]}")Building a Vector Search System
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with OpenAI embeddings
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="your-api-key",
model_name="text-embedding-3-small"
)
client = chromadb.PersistentClient(path="./chroma_db")
# Create or get collection
collection = client.get_or_create_collection(
name="documents",
embedding_function=openai_ef,
metadata={"hnsw:space": "cosine"} # Use cosine similarity
)
# Add documents
documents = [
"FastAPI is a modern Python web framework",
"Django provides batteries-included web development",
"Flask is a lightweight WSGI application",
"React is a JavaScript library for building UIs",
"Vue.js is a progressive JavaScript framework"
]
collection.add(
documents=documents,
ids=[f"doc_{i}" for i in range(len(documents))],
metadatas=[{"category": "python" if "Python" in d else "javascript"}
for d in documents]
)
# Query with filters
results = collection.query(
query_texts=["What's a good Python web framework?"],
n_results=3,
where={"category": "python"} # Filter by metadata
)
for doc, distance in zip(results["documents"][0], results["distances"][0]):
print(f"Distance: {distance:.4f} | {doc}")Production-Ready RAG with pgvector
import psycopg2
from pgvector.psycopg2 import register_vector
from openai import OpenAI
import numpy as np
# Connect to PostgreSQL with pgvector extension
conn = psycopg2.connect("postgresql://user:pass@localhost/vectordb")
register_vector(conn)
client = OpenAI()
def setup_database():
"""Create table with vector column."""
with conn.cursor() as cur:
cur.execute("CREATE EXTENSION IF NOT EXISTS vector")
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
embedding vector(1536),
metadata JSONB,
created_at TIMESTAMP DEFAULT NOW()
)
""")
cur.execute("""
CREATE INDEX IF NOT EXISTS documents_embedding_idx
ON documents USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100)
""")
conn.commit()
def add_document(content: str, metadata: dict = None):
"""Add document with embedding."""
response = client.embeddings.create(
input=content,
model="text-embedding-3-small"
)
embedding = response.data[0].embedding
with conn.cursor() as cur:
cur.execute(
"""INSERT INTO documents (content, embedding, metadata)
VALUES (%s, %s, %s) RETURNING id""",
(content, embedding, metadata)
)
doc_id = cur.fetchone()[0]
conn.commit()
return doc_id
def search_similar(query: str, limit: int = 5) -> list:
"""Find similar documents using vector search."""
response = client.embeddings.create(
input=query,
model="text-embedding-3-small"
)
query_embedding = response.data[0].embedding
with conn.cursor() as cur:
cur.execute("""
SELECT id, content, 1 - (embedding <=> %s) as similarity
FROM documents
ORDER BY embedding <=> %s
LIMIT %s
""", (query_embedding, query_embedding, limit))
return [{"id": row[0], "content": row[1], "similarity": row[2]}
for row in cur.fetchall()]
# Usage
setup_database()
add_document("PostgreSQL is a powerful relational database", {"type": "database"})
add_document("MongoDB is a document-oriented NoSQL database", {"type": "database"})
results = search_similar("What database should I use for structured data?")
for r in results:
print(f"[{r['similarity']:.4f}] {r['content']}")Chunking Strategies for Long Documents
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
TokenTextSplitter,
MarkdownHeaderTextSplitter
)
# Strategy 1: Recursive Character Splitting (most common)
recursive_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ". ", " ", ""]
)
# Strategy 2: Token-based splitting (respects model limits)
token_splitter = TokenTextSplitter(
chunk_size=500,
chunk_overlap=50,
encoding_name="cl100k_base" # GPT-4 tokenizer
)
# Strategy 3: Semantic chunking by headers
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
)
# Custom chunking with context preservation
def chunk_with_context(text: str, chunk_size: int = 1000) -> list[dict]:
"""Chunk text while preserving document context."""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=200
)
chunks = splitter.split_text(text)
return [
{
"content": chunk,
"chunk_index": i,
"total_chunks": len(chunks),
"start_char": text.find(chunk[:50]),
}
for i, chunk in enumerate(chunks)
]Hybrid Search: Combining Dense and Sparse
from rank_bm25 import BM25Okapi
import numpy as np
class HybridSearcher:
"""Combine BM25 (keyword) with dense vector search."""
def __init__(self, documents: list[str], embeddings: np.ndarray):
self.documents = documents
self.embeddings = embeddings
# Initialize BM25 for sparse search
tokenized = [doc.lower().split() for doc in documents]
self.bm25 = BM25Okapi(tokenized)
def search(self, query: str, query_embedding: np.ndarray,
alpha: float = 0.5, top_k: int = 5) -> list[dict]:
"""
Hybrid search combining dense and sparse scores.
alpha: weight for dense search (1-alpha for sparse)
"""
# Dense search scores
dense_scores = np.dot(self.embeddings, query_embedding) / (
np.linalg.norm(self.embeddings, axis=1) * np.linalg.norm(query_embedding)
)
# Sparse search scores (BM25)
sparse_scores = self.bm25.get_scores(query.lower().split())
# Normalize scores to [0, 1]
dense_norm = (dense_scores - dense_scores.min()) / (dense_scores.max() - dense_scores.min() + 1e-8)
sparse_norm = (sparse_scores - sparse_scores.min()) / (sparse_scores.max() - sparse_scores.min() + 1e-8)
# Combine scores
hybrid_scores = alpha * dense_norm + (1 - alpha) * sparse_norm
# Get top results
top_indices = np.argsort(hybrid_scores)[::-1][:top_k]
return [
{
"document": self.documents[i],
"score": hybrid_scores[i],
"dense_score": dense_scores[i],
"sparse_score": sparse_scores[i]
}
for i in top_indices
]References
- OpenAI Embeddings: https://platform.openai.com/docs/guides/embeddings
- Sentence Transformers: https://www.sbert.net/
- ChromaDB: https://docs.trychroma.com/
- pgvector: https://github.com/pgvector/pgvector
- MTEB Benchmark: https://huggingface.co/spaces/mteb/leaderboard
Conclusion
Vector embeddings have become essential infrastructure for modern AI applications. Whether you’re building semantic search, RAG systems, or recommendation engines, understanding how to generate, store, and query embeddings effectively is crucial. Start with a hosted solution like OpenAI’s embeddings for simplicity, consider local models like Sentence Transformers for cost control, and choose your vector database based on scale and operational requirements. The combination of dense embeddings with sparse methods like BM25 often yields the best results for production search systems.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.