Every major cloud provider now offers managed services for LLM operations. But they’re not created equal—each has different strengths, pricing models, and integration patterns.
I’ve deployed LLM applications across all three major clouds. Here’s an honest comparison of what works, what doesn’t, and how to choose.
Series Navigation: Part 7: MLOps/LLMOps Fundamentals → Part 8: Cloud Platforms (You are here) → Part 9: DIY Implementation
Cloud LLMOps Architecture Overview
Before diving into specific platforms, let’s understand the common architectural patterns that all cloud LLMOps solutions share:
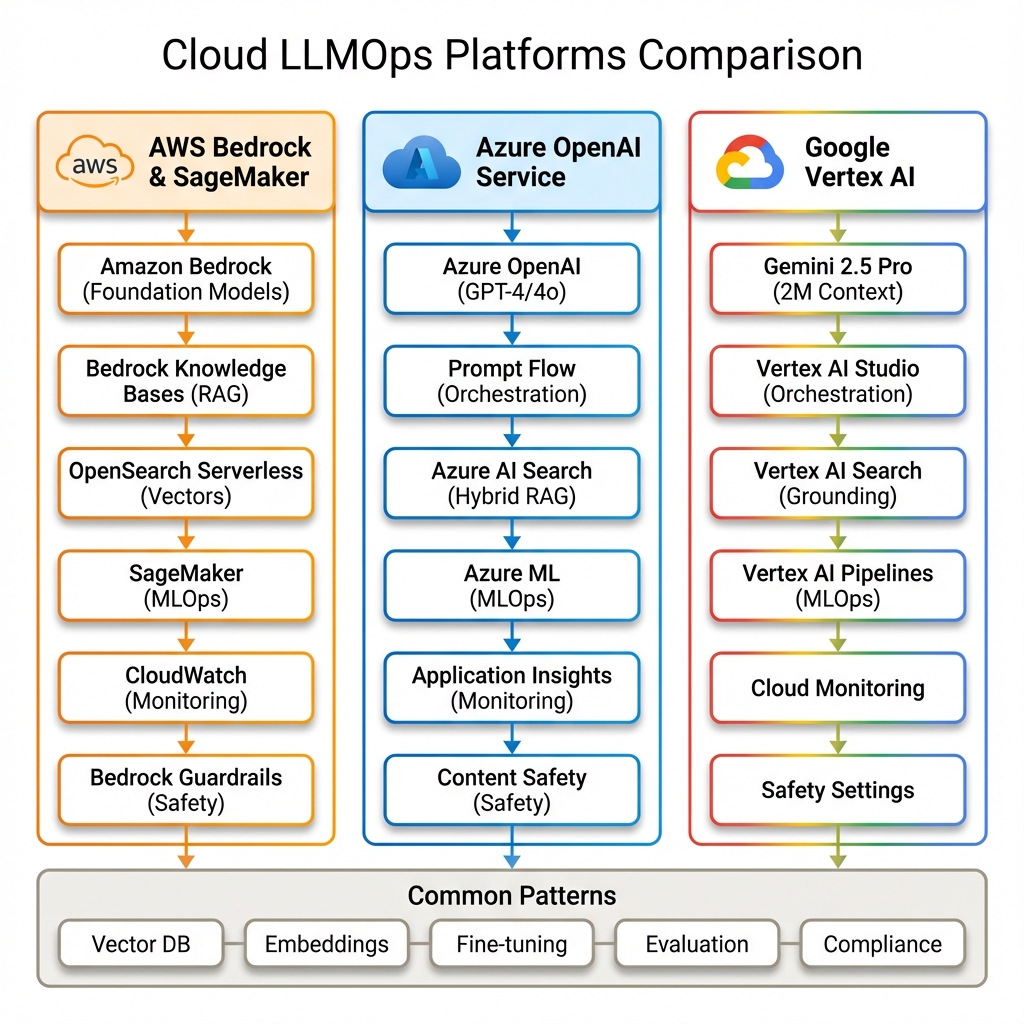
All three platforms provide similar core capabilities:
- Model Access: Pre-trained foundation models via API
- Fine-tuning: Customize models with your data
- Vector Databases: For semantic search and RAG
- Orchestration: Workflow and prompt management
- Observability: Logging, monitoring, and evaluation
- Governance: Content filtering and compliance
AWS: Amazon Bedrock & SageMaker
AWS offers the most comprehensive suite, but it’s spread across multiple services that you need to integrate yourself.
🏗️ Architecture
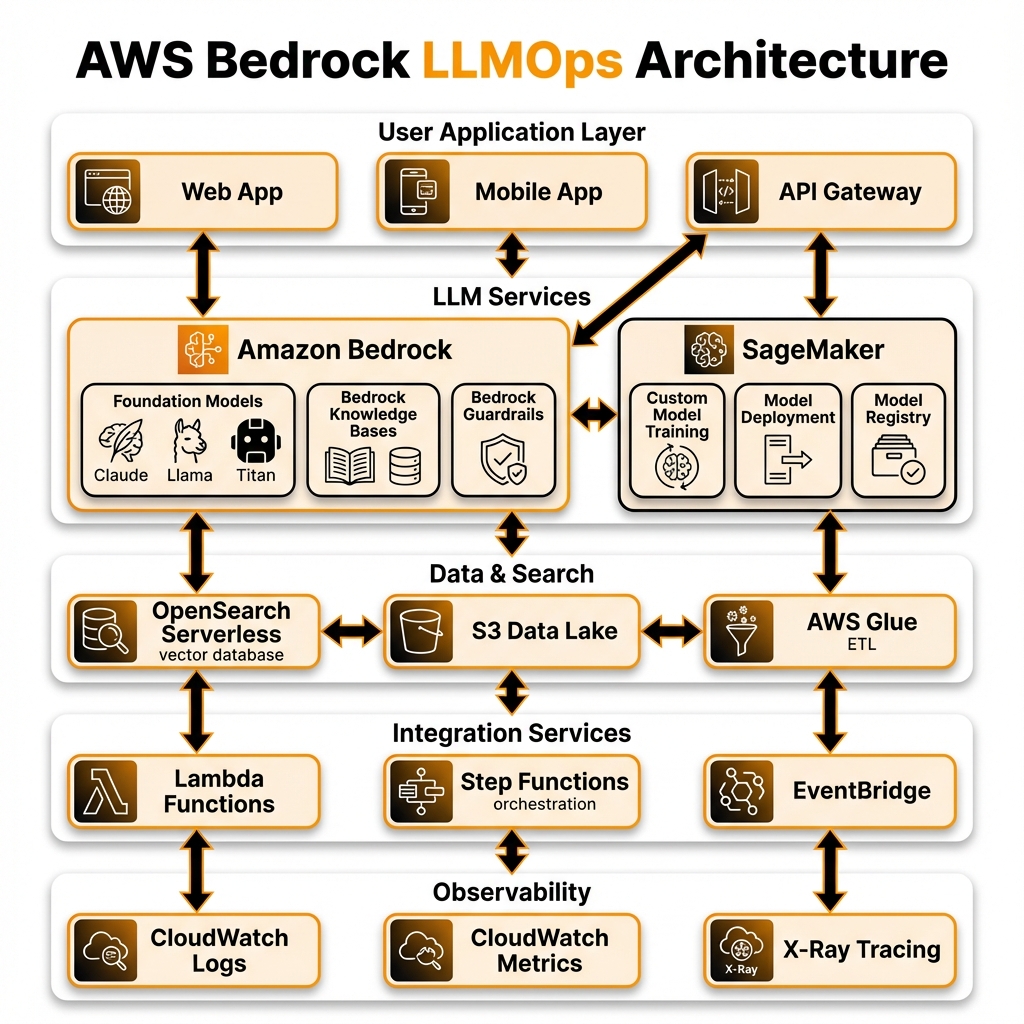
🎯 Key Services
- Amazon Bedrock: Access to foundation models (Claude, Llama, Titan, Mistral)
- Bedrock Knowledge Bases: Managed RAG with vector search
- Bedrock Guardrails: Content filtering and safety policies
- SageMaker: For custom model training and deployment
- OpenSearch Serverless: Vector database for embeddings
- S3 + Glue: Data lake and ETL
✅ Strengths
- Model Variety: Widest selection of foundation models (Anthropic, Meta, Amazon, Cohere, AI21)
- Flexible Deployment: Serverless (Bedrock) or dedicated instances (SageMaker)
- Enterprise Ready: Strong compliance (HIPAA, GDPR, SOC2)
- Cost Options: Pay-per-token or provisioned throughput
- Ecosystem Integration: Deep integration with AWS services (Lambda, Step Functions, EventBridge)
❌ Weaknesses
- Fragmented: Multiple services to stitch together (Bedrock + SageMaker + OpenSearch)
- No Built-in Prompt Flow: Need to build orchestration yourself
- Learning Curve: IAM policies, VPCs, and AWS complexity
- No Native OpenAI: Must use third-party API proxy or SageMaker endpoints
💡 Best For
- Teams already invested in AWS
- Need diverse model options (not locked into OpenAI)
- Require custom model training (SageMaker)
- Building complex event-driven workflows
Azure: Azure OpenAI & Azure ML
Azure has the strongest enterprise story—especially if you need OpenAI models with enterprise compliance (HIPAA, SOC2, etc.).
🏗️ Architecture
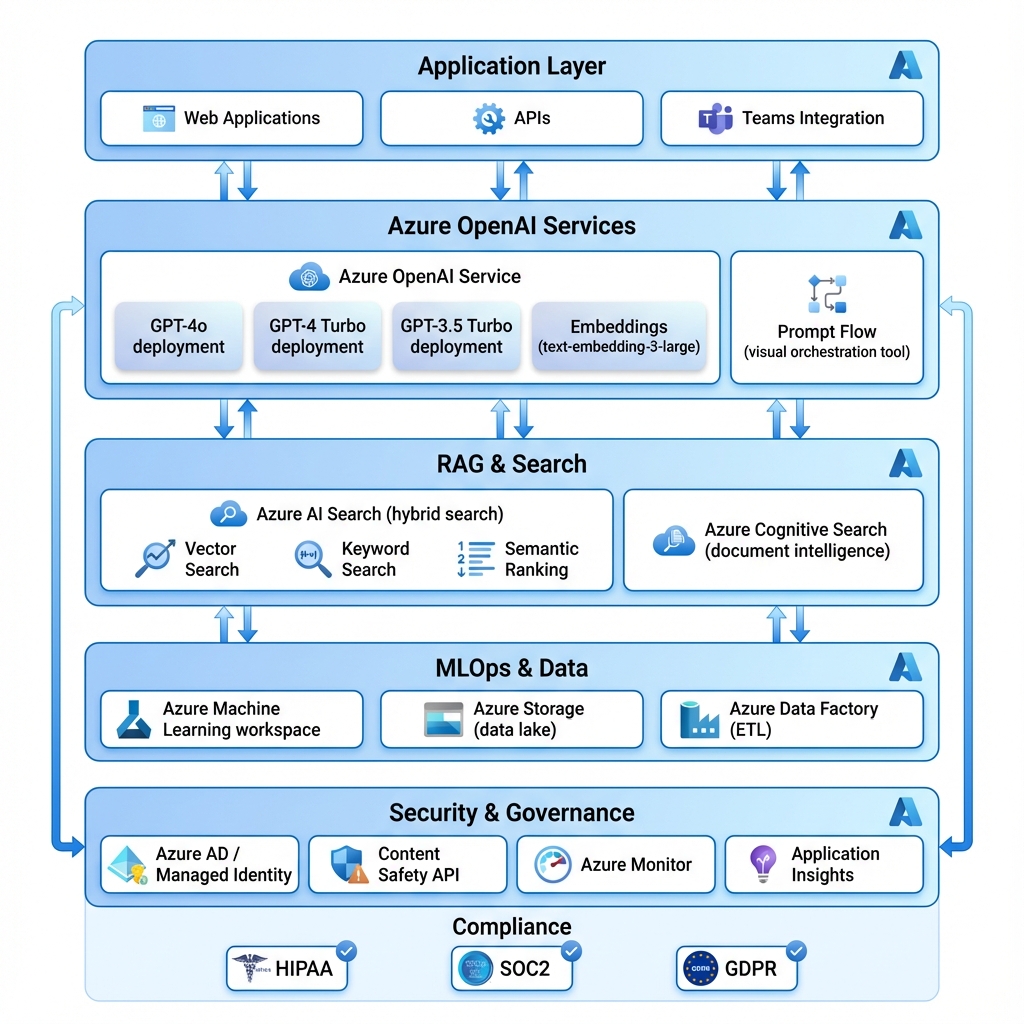
🎯 Key Services
- Azure OpenAI Service: GPT-4, GPT-4o, GPT-3.5 Turbo with enterprise SLA
- Azure AI Search: Hybrid search (vector + keyword + semantic ranking)
- Prompt Flow: Visual LLMOps orchestration (like Langflow but managed)
- Azure ML: Model training, deployment, monitoring
- Azure Cognitive Search: Document intelligence and OCR
- Content Safety: Built-in harm detection
✅ Strengths
- OpenAI Models with Compliance: Same models as OpenAI, but with enterprise SLA, data residency, and compliance
- Prompt Flow: Best-in-class visual orchestration for LLM workflows
- Hybrid Search: Azure AI Search combines vector, keyword, and semantic ranking out of the box
- Managed Identity Support: No API keys needed, use Azure AD for auth
- Microsoft Ecosystem: Integrates with Teams, SharePoint, Power Platform
❌ Weaknesses
- Limited Model Variety: Primarily OpenAI models (no Claude, Llama requires Azure ML)
- Regional Availability: Not all models available in all regions
- Quota Management: Need to request quota increases for GPT-4
- Cost: Can be more expensive than AWS Bedrock for high-volume use
💡 Best For
- Enterprises needing OpenAI models with compliance
- Microsoft/Office 365 shops
- Teams wanting visual LLMOps (Prompt Flow)
- Need for hybrid search (vector + keyword)
Google Cloud: Vertex AI
GCP’s Vertex AI offers the most integrated experience—everything in one platform with Gemini models that have industry-leading context windows.
🎯 Key Services
- Vertex AI Studio: Unified platform for LLM development
- Gemini Models: 1M-2M token context windows (game-changing for long documents)
- Vertex AI Search: RAG with grounding on your data
- Model Garden: Access to Gemini, PaLM, Llama, Mistral
- Vertex AI Workbench: Managed Jupyter for experimentation
- Vertex AI Pipelines: MLOps orchestration with Kubeflow
✅ Strengths
- Unified Platform: Everything in one place—Vertex AI handles models, RAG, evaluation, deployment
- Gemini’s Context Window: 2M tokens = entire codebases or books in one prompt
- Grounding with Google Search: RAG that can use live Google Search results
- Simplest API: Clean, Pythonic SDK
- Best for Multimodal: Gemini excels at images, video, audio, and code
❌ Weaknesses
- Smaller Ecosystem: Fewer third-party integrations than AWS/Azure
- No OpenAI Models: Must use Gemini or open-source models
- Regional Limitations: Some features only in specific regions
- Less Mature: Newer than AWS/Azure LLMOps offerings
💡 Best For
- Teams wanting a unified, simple platform
- Processing very long documents (2M context)
- Multimodal applications (images, video, audio)
- Need grounding with live Google Search
Platform Comparison
| Feature | AWS Bedrock | Azure OpenAI | GCP Vertex AI |
|---|---|---|---|
| Foundation Models | Claude, Llama, Titan, Mistral, Cohere | GPT-4, GPT-4o, GPT-3.5, GPT-4 Turbo | Gemini, PaLM, Llama, Claude |
| Max Context | 200K (Claude 3) | 128K (GPT-4 Turbo) | 2M (Gemini 2.5) |
| RAG Platform | Bedrock KB + OpenSearch | Azure AI Search (Hybrid) | Vertex AI Search + Grounding |
| Orchestration | Step Functions / Custom | Prompt Flow (Visual) | Vertex AI Pipelines |
| Cost Model | Pay-per-token or Provisioned | Pay-per-token or PTU | Pay-per-token or Reserved |
| Best for RAG | Bedrock Knowledge Bases | Azure AI Search (Best hybrid) | Grounding with Google Search |
| Content Safety | Bedrock Guardrails | Azure Content Safety | Safety Settings API |
| MLOps Integration | SageMaker (Most mature) | Azure ML | Vertex AI (Most unified) |
| Compliance | HIPAA, SOC2, GDPR | HIPAA, SOC2, GDPR (Best) | HIPAA, SOC2, GDPR |
| Pricing (1M tokens) | $3-8 (Claude 3) | $10-30 (GPT-4) | $1.25-7 (Gemini) |
Key Takeaways
- Azure: Best for enterprise compliance and OpenAI models with Prompt Flow for LLMOps
- AWS: Most model variety with Bedrock, requires more integration work
- GCP: Most integrated platform, Gemini’s 2M context is game-changing for large docs
- Multi-cloud: Use LiteLLM or similar to abstract away provider differences
What’s Next
In Part 9, we’ll build our own LLMOps platform using open-source tools—Kubernetes, GitHub Actions, MLflow, and more. Complete control, no vendor lock-in.
References & Further Reading
- Amazon Bedrock Documentation
- Azure OpenAI Service
- Vertex AI Documentation
- Azure AI Search
- AWS RAG Best Practices
Which cloud are you using for LLMOps? Share your experience on GitHub or LinkedIn.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.