Introduction: Modern Python has evolved dramatically with features that transform how we build data engineering systems. This comprehensive guide explores advanced Python patterns including structural pattern matching, async/await for concurrent data processing, dataclasses and Pydantic for robust data validation, and context managers for resource management. After building production data pipelines across multiple organizations, I’ve found that leveraging these modern patterns significantly improves code maintainability, reduces bugs, and enhances performance. Organizations should adopt these patterns systematically, starting with type hints and dataclasses for immediate wins, then progressing to async patterns for I/O-bound workloads.
Structural Pattern Matching for Data Processing
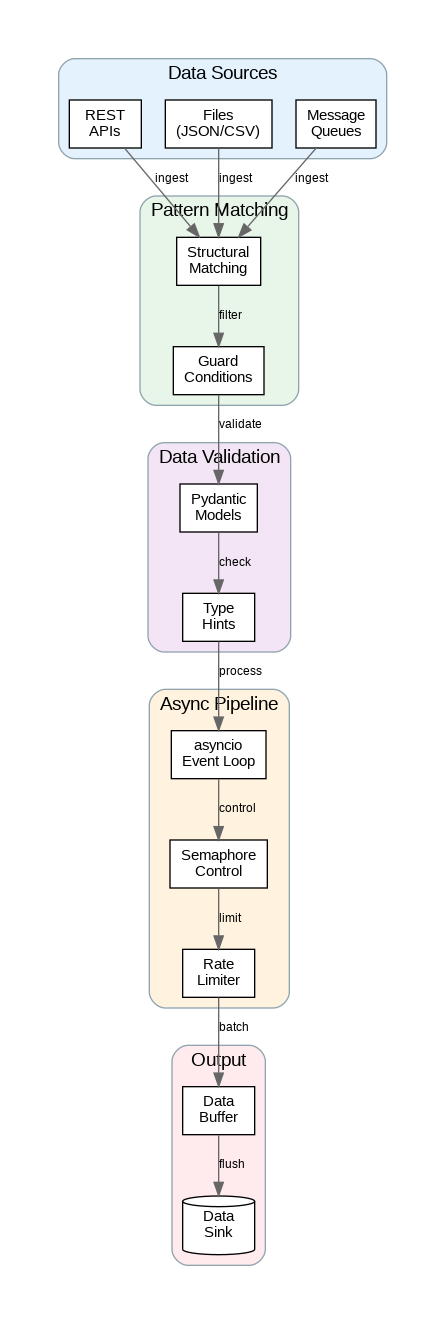
Python 3.10 introduced structural pattern matching, a powerful feature that transforms how we handle complex data structures. Unlike simple switch statements, pattern matching enables destructuring, type checking, and guard conditions in a single, readable construct. For data engineering, this means cleaner ETL logic, better error handling, and more maintainable transformation code.
Pattern matching excels at processing heterogeneous data sources. When ingesting data from APIs, files, or message queues, records often have varying structures. Traditional if-elif chains become unwieldy; pattern matching provides elegant alternatives that clearly express intent while handling edge cases gracefully.
Guard conditions add runtime checks to patterns, enabling complex matching logic. Combine structural patterns with guards to validate data ranges, check business rules, or filter records during transformation. This approach centralizes validation logic, making pipelines easier to test and modify.
Async Patterns for High-Throughput Pipelines
Asynchronous programming transforms I/O-bound data pipelines from sequential bottlenecks to concurrent powerhouses. When fetching data from multiple APIs, reading from databases, or writing to cloud storage, async patterns enable thousands of concurrent operations without thread overhead. Understanding when and how to apply async patterns is crucial for modern data engineering.
The asyncio library provides the foundation for async Python. Event loops manage concurrent coroutines, while async/await syntax makes asynchronous code readable. For data pipelines, combine asyncio with libraries like aiohttp for HTTP requests, aioboto3 for AWS services, and asyncpg for PostgreSQL to achieve massive throughput improvements.
Semaphores and rate limiters prevent overwhelming downstream systems. Even with async capabilities, external APIs and databases have limits. Implement backpressure mechanisms using asyncio.Semaphore to control concurrency, and use token bucket algorithms for precise rate limiting. These patterns ensure reliable operation under varying load conditions.
Python Implementation: Modern Data Processing Patterns
Here’s a comprehensive implementation demonstrating modern Python patterns for data engineering:
"""Modern Python Patterns for Data Engineering"""
import asyncio
import aiohttp
from dataclasses import dataclass, field
from typing import Optional, List, Dict, Any, AsyncIterator, TypeVar, Generic
from pydantic import BaseModel, Field, validator, root_validator
from contextlib import asynccontextmanager
from datetime import datetime, timedelta
from enum import Enum, auto
import logging
from functools import wraps
import time
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
T = TypeVar('T')
# ==================== Structural Pattern Matching ====================
class RecordType(Enum):
"""Types of data records."""
USER_EVENT = auto()
TRANSACTION = auto()
SYSTEM_LOG = auto()
METRIC = auto()
@dataclass
class ProcessedRecord:
"""Result of record processing."""
record_type: RecordType
data: Dict[str, Any]
timestamp: datetime
metadata: Dict[str, Any] = field(default_factory=dict)
def process_record(record: Dict[str, Any]) -> Optional[ProcessedRecord]:
"""Process records using structural pattern matching."""
match record:
# User event with required fields
case {"type": "user_event", "user_id": str(uid), "action": str(action), "timestamp": ts} if uid and action:
return ProcessedRecord(
record_type=RecordType.USER_EVENT,
data={"user_id": uid, "action": action},
timestamp=datetime.fromisoformat(ts),
metadata={"source": "user_events"}
)
# Transaction with amount validation
case {"type": "transaction", "amount": float(amt), "currency": str(curr)} if amt > 0:
return ProcessedRecord(
record_type=RecordType.TRANSACTION,
data={"amount": amt, "currency": curr},
timestamp=datetime.utcnow(),
metadata={"validated": True}
)
# System log with severity levels
case {"type": "log", "level": ("ERROR" | "CRITICAL") as level, "message": str(msg)}:
return ProcessedRecord(
record_type=RecordType.SYSTEM_LOG,
data={"level": level, "message": msg, "priority": "high"},
timestamp=datetime.utcnow(),
)
case {"type": "log", "level": str(level), "message": str(msg)}:
return ProcessedRecord(
record_type=RecordType.SYSTEM_LOG,
data={"level": level, "message": msg, "priority": "normal"},
timestamp=datetime.utcnow(),
)
# Metric with nested structure
case {"type": "metric", "name": str(name), "value": int(val) | float(val), "tags": dict(tags)}:
return ProcessedRecord(
record_type=RecordType.METRIC,
data={"name": name, "value": val, "tags": tags},
timestamp=datetime.utcnow(),
)
# Unknown or invalid record
case _:
logger.warning(f"Unknown record format: {record}")
return None
# ==================== Pydantic Models for Validation ====================
class DataSourceConfig(BaseModel):
"""Configuration for data sources with validation."""
name: str = Field(..., min_length=1, max_length=100)
url: str = Field(..., regex=r'^https?://')
batch_size: int = Field(default=1000, ge=1, le=10000)
timeout_seconds: float = Field(default=30.0, ge=1.0, le=300.0)
retry_attempts: int = Field(default=3, ge=0, le=10)
headers: Dict[str, str] = Field(default_factory=dict)
@validator('name')
def validate_name(cls, v):
"""Ensure name is alphanumeric with underscores."""
if not v.replace('_', '').replace('-', '').isalnum():
raise ValueError('Name must be alphanumeric with underscores/hyphens')
return v.lower()
@root_validator
def validate_config(cls, values):
"""Cross-field validation."""
batch_size = values.get('batch_size', 1000)
timeout = values.get('timeout_seconds', 30.0)
# Ensure timeout is sufficient for batch size
min_timeout = batch_size / 100 # 100 records per second minimum
if timeout < min_timeout:
values['timeout_seconds'] = min_timeout
return values
class PipelineMetrics(BaseModel):
"""Metrics for pipeline monitoring."""
records_processed: int = 0
records_failed: int = 0
processing_time_ms: float = 0.0
start_time: datetime = Field(default_factory=datetime.utcnow)
end_time: Optional[datetime] = None
@property
def success_rate(self) -> float:
"""Calculate success rate."""
total = self.records_processed + self.records_failed
return self.records_processed / total if total > 0 else 0.0
@property
def throughput(self) -> float:
"""Calculate records per second."""
if self.processing_time_ms > 0:
return (self.records_processed / self.processing_time_ms) * 1000
return 0.0
# ==================== Async Data Pipeline ====================
class AsyncRateLimiter:
"""Token bucket rate limiter for async operations."""
def __init__(self, rate: float, burst: int = 1):
self.rate = rate # tokens per second
self.burst = burst
self.tokens = burst
self.last_update = time.monotonic()
self._lock = asyncio.Lock()
async def acquire(self) -> None:
"""Acquire a token, waiting if necessary."""
async with self._lock:
now = time.monotonic()
elapsed = now - self.last_update
self.tokens = min(self.burst, self.tokens + elapsed * self.rate)
self.last_update = now
if self.tokens < 1:
wait_time = (1 - self.tokens) / self.rate
await asyncio.sleep(wait_time)
self.tokens = 0
else:
self.tokens -= 1
class AsyncDataPipeline:
"""High-throughput async data pipeline."""
def __init__(
self,
config: DataSourceConfig,
concurrency: int = 10,
rate_limit: float = 100.0
):
self.config = config
self.concurrency = concurrency
self.semaphore = asyncio.Semaphore(concurrency)
self.rate_limiter = AsyncRateLimiter(rate_limit, burst=concurrency)
self.metrics = PipelineMetrics()
self._session: Optional[aiohttp.ClientSession] = None
@asynccontextmanager
async def session(self):
"""Managed HTTP session context."""
if self._session is None or self._session.closed:
timeout = aiohttp.ClientTimeout(total=self.config.timeout_seconds)
self._session = aiohttp.ClientSession(
headers=self.config.headers,
timeout=timeout
)
try:
yield self._session
finally:
pass # Keep session open for reuse
async def close(self):
"""Close the HTTP session."""
if self._session and not self._session.closed:
await self._session.close()
async def fetch_batch(self, batch_id: int) -> List[Dict[str, Any]]:
"""Fetch a batch of records with rate limiting and retries."""
await self.rate_limiter.acquire()
async with self.semaphore:
for attempt in range(self.config.retry_attempts):
try:
async with self.session() as session:
url = f"{self.config.url}?batch={batch_id}&size={self.config.batch_size}"
async with session.get(url) as response:
if response.status == 200:
data = await response.json()
return data.get('records', [])
elif response.status == 429: # Rate limited
retry_after = int(response.headers.get('Retry-After', 5))
await asyncio.sleep(retry_after)
else:
logger.warning(f"Batch {batch_id} failed: {response.status}")
except asyncio.TimeoutError:
logger.warning(f"Batch {batch_id} timeout, attempt {attempt + 1}")
except Exception as e:
logger.error(f"Batch {batch_id} error: {e}")
if attempt < self.config.retry_attempts - 1:
await asyncio.sleep(2 ** attempt) # Exponential backoff
return []
async def process_records(
self,
records: List[Dict[str, Any]]
) -> AsyncIterator[ProcessedRecord]:
"""Process records asynchronously."""
for record in records:
processed = process_record(record)
if processed:
self.metrics.records_processed += 1
yield processed
else:
self.metrics.records_failed += 1
async def run(self, num_batches: int) -> PipelineMetrics:
"""Run the pipeline for specified number of batches."""
start_time = time.monotonic()
self.metrics = PipelineMetrics()
try:
# Fetch all batches concurrently
tasks = [self.fetch_batch(i) for i in range(num_batches)]
batches = await asyncio.gather(*tasks, return_exceptions=True)
# Process records
for batch in batches:
if isinstance(batch, list):
async for record in self.process_records(batch):
# Here you would write to destination
pass
else:
logger.error(f"Batch failed: {batch}")
finally:
await self.close()
self.metrics.processing_time_ms = (time.monotonic() - start_time) * 1000
self.metrics.end_time = datetime.utcnow()
return self.metrics
# ==================== Context Managers for Resources ====================
@asynccontextmanager
async def managed_pipeline(config: DataSourceConfig):
"""Context manager for pipeline lifecycle."""
pipeline = AsyncDataPipeline(config)
logger.info(f"Starting pipeline: {config.name}")
try:
yield pipeline
except Exception as e:
logger.error(f"Pipeline error: {e}")
raise
finally:
await pipeline.close()
logger.info(f"Pipeline closed: {config.name}")
# ==================== Decorator Patterns ====================
def retry_async(max_attempts: int = 3, delay: float = 1.0):
"""Decorator for async retry logic."""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
last_exception = None
for attempt in range(max_attempts):
try:
return await func(*args, **kwargs)
except Exception as e:
last_exception = e
if attempt < max_attempts - 1:
await asyncio.sleep(delay * (2 ** attempt))
logger.warning(f"Retry {attempt + 1}/{max_attempts}: {e}")
raise last_exception
return wrapper
return decorator
def measure_time(func):
"""Decorator to measure execution time."""
@wraps(func)
async def async_wrapper(*args, **kwargs):
start = time.monotonic()
result = await func(*args, **kwargs)
elapsed = (time.monotonic() - start) * 1000
logger.info(f"{func.__name__} completed in {elapsed:.2f}ms")
return result
@wraps(func)
def sync_wrapper(*args, **kwargs):
start = time.monotonic()
result = func(*args, **kwargs)
elapsed = (time.monotonic() - start) * 1000
logger.info(f"{func.__name__} completed in {elapsed:.2f}ms")
return result
if asyncio.iscoroutinefunction(func):
return async_wrapper
return sync_wrapper
# ==================== Generic Data Structures ====================
class DataBuffer(Generic[T]):
"""Generic buffer for batching data."""
def __init__(self, max_size: int = 1000, flush_interval: float = 5.0):
self.max_size = max_size
self.flush_interval = flush_interval
self._buffer: List[T] = []
self._last_flush = time.monotonic()
self._lock = asyncio.Lock()
async def add(self, item: T) -> Optional[List[T]]:
"""Add item to buffer, return batch if flush needed."""
async with self._lock:
self._buffer.append(item)
if self._should_flush():
return await self._flush()
return None
def _should_flush(self) -> bool:
"""Check if buffer should be flushed."""
if len(self._buffer) >= self.max_size:
return True
if time.monotonic() - self._last_flush >= self.flush_interval:
return True
return False
async def _flush(self) -> List[T]:
"""Flush buffer and return contents."""
batch = self._buffer.copy()
self._buffer.clear()
self._last_flush = time.monotonic()
return batch
async def flush_remaining(self) -> List[T]:
"""Flush any remaining items."""
async with self._lock:
return await self._flush()
# ==================== Example Usage ====================
async def main():
"""Example pipeline execution."""
# Configure data source
config = DataSourceConfig(
name="user_events_api",
url="https://api.example.com/events",
batch_size=500,
timeout_seconds=30.0,
retry_attempts=3
)
# Run pipeline with context manager
async with managed_pipeline(config) as pipeline:
metrics = await pipeline.run(num_batches=10)
print(f"Records processed: {metrics.records_processed}")
print(f"Records failed: {metrics.records_failed}")
print(f"Success rate: {metrics.success_rate:.2%}")
print(f"Throughput: {metrics.throughput:.2f} records/sec")
print(f"Processing time: {metrics.processing_time_ms:.2f}ms")
if __name__ == "__main__":
asyncio.run(main())Type Hints and Static Analysis
Type hints transform Python from a dynamically typed language into one with optional static typing. For data engineering, this means catching type mismatches before runtime, improving IDE support, and creating self-documenting code. Modern type hints support generics, protocols, and complex nested structures essential for data pipeline development.
Tools like mypy and pyright perform static analysis on type-annotated code. Configure strict mode to catch subtle bugs that would otherwise surface only in production. Integrate type checking into CI/CD pipelines to prevent type errors from reaching deployment. The upfront investment in type annotations pays dividends in reduced debugging time and improved code quality.
Protocol classes enable structural subtyping, allowing duck typing with type safety. Define protocols for data sources, transformers, and sinks to create flexible, pluggable pipeline components. This approach combines Python’s dynamic flexibility with static type guarantees, enabling robust data engineering architectures.
Key Takeaways and Best Practices
Modern Python patterns significantly improve data engineering code quality and performance. Adopt structural pattern matching for complex data transformation logic. Use async/await for I/O-bound operations to achieve high throughput. Leverage Pydantic for robust data validation with clear error messages. Implement type hints throughout your codebase for better tooling support and documentation.
The code examples provided here establish patterns for production-ready data pipelines. Start with type hints and dataclasses for immediate improvements, then progressively adopt async patterns as your pipeline’s I/O requirements grow. In the next article, we’ll explore building production data pipelines with Apache Airflow using these modern Python patterns.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.