Introduction: Real-time data streaming has become essential for modern data architectures, enabling immediate insights and actions on data as it arrives. This comprehensive guide explores production streaming patterns using Apache Kafka and Python, covering producer/consumer design, stream processing with Flink, exactly-once semantics, and operational best practices. After building streaming platforms processing billions of events daily, I’ve learned that success depends on understanding delivery guarantees, designing for failure recovery, and implementing proper monitoring. Organizations should adopt streaming incrementally, starting with simple event pipelines before progressing to complex stream processing topologies.
Kafka Architecture for Data Engineers
Apache Kafka provides the foundation for most real-time data architectures, offering durable, scalable message streaming with strong ordering guarantees. Understanding Kafka’s architecture—brokers, topics, partitions, and consumer groups—is essential for designing effective streaming systems. Each architectural decision impacts throughput, latency, and fault tolerance.
Partitioning strategy determines parallelism and ordering guarantees. Messages with the same key route to the same partition, ensuring ordering for related events. Choose partition keys carefully—user IDs for user-centric applications, device IDs for IoT, or transaction IDs for financial systems. Over-partitioning wastes resources; under-partitioning limits throughput. Start with partition counts that match expected consumer parallelism.
Replication provides fault tolerance by maintaining copies of partitions across brokers. Configure replication factor based on durability requirements—typically 3 for production workloads. Understand the trade-off between acks settings and latency: acks=all provides strongest durability but highest latency; acks=1 offers lower latency with some durability risk.
Producer and Consumer Patterns
Effective producer design balances throughput, latency, and reliability. Batch messages for higher throughput using linger.ms and batch.size settings. Enable compression (lz4 or zstd) to reduce network bandwidth and storage. Implement idempotent producers to handle retries without duplicates. Use asynchronous sends with callbacks for high-throughput scenarios.
Consumer group design enables parallel processing while maintaining ordering guarantees. Each partition assigns to exactly one consumer within a group, enabling horizontal scaling up to the partition count. Design consumers to handle rebalancing gracefully—save offsets before rebalance, restore state after. Implement proper error handling to prevent poison messages from blocking consumption.
Offset management controls message delivery semantics. Auto-commit provides at-least-once delivery with potential duplicates during failures. Manual commit with processing enables exactly-once semantics when combined with idempotent downstream operations. Choose commit strategies based on application requirements and tolerance for duplicates or data loss.
Python Implementation: Production Streaming Pipeline
Here’s a comprehensive implementation demonstrating production streaming patterns with Kafka and Python:
"""Production Real-Time Streaming Pipeline with Kafka"""
import json
import logging
import time
from typing import Dict, Any, List, Optional, Callable
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from abc import ABC, abstractmethod
from concurrent.futures import ThreadPoolExecutor
import threading
from collections import defaultdict
from confluent_kafka import Producer, Consumer, KafkaError, KafkaException
from confluent_kafka.admin import AdminClient, NewTopic
from confluent_kafka.serialization import StringSerializer, StringDeserializer
import prometheus_client
from prometheus_client import Counter, Histogram, Gauge
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# ==================== Metrics ====================
MESSAGES_PRODUCED = Counter(
'kafka_messages_produced_total',
'Total messages produced',
['topic']
)
MESSAGES_CONSUMED = Counter(
'kafka_messages_consumed_total',
'Total messages consumed',
['topic', 'consumer_group']
)
PROCESSING_TIME = Histogram(
'message_processing_seconds',
'Time spent processing messages',
['topic']
)
CONSUMER_LAG = Gauge(
'kafka_consumer_lag',
'Consumer lag in messages',
['topic', 'partition', 'consumer_group']
)
# ==================== Configuration ====================
@dataclass
class KafkaConfig:
"""Kafka connection configuration."""
bootstrap_servers: str = "localhost:9092"
security_protocol: str = "PLAINTEXT"
sasl_mechanism: Optional[str] = None
sasl_username: Optional[str] = None
sasl_password: Optional[str] = None
def to_dict(self) -> Dict[str, Any]:
config = {
"bootstrap.servers": self.bootstrap_servers,
"security.protocol": self.security_protocol,
}
if self.sasl_mechanism:
config["sasl.mechanism"] = self.sasl_mechanism
config["sasl.username"] = self.sasl_username
config["sasl.password"] = self.sasl_password
return config
@dataclass
class ProducerConfig:
"""Producer-specific configuration."""
acks: str = "all"
retries: int = 3
retry_backoff_ms: int = 100
linger_ms: int = 5
batch_size: int = 16384
compression_type: str = "lz4"
enable_idempotence: bool = True
def to_dict(self) -> Dict[str, Any]:
return {
"acks": self.acks,
"retries": self.retries,
"retry.backoff.ms": self.retry_backoff_ms,
"linger.ms": self.linger_ms,
"batch.size": self.batch_size,
"compression.type": self.compression_type,
"enable.idempotence": self.enable_idempotence,
}
@dataclass
class ConsumerConfig:
"""Consumer-specific configuration."""
group_id: str = "default-group"
auto_offset_reset: str = "earliest"
enable_auto_commit: bool = False
max_poll_interval_ms: int = 300000
session_timeout_ms: int = 45000
max_poll_records: int = 500
def to_dict(self) -> Dict[str, Any]:
return {
"group.id": self.group_id,
"auto.offset.reset": self.auto_offset_reset,
"enable.auto.commit": self.enable_auto_commit,
"max.poll.interval.ms": self.max_poll_interval_ms,
"session.timeout.ms": self.session_timeout_ms,
}
# ==================== Message Types ====================
@dataclass
class Message:
"""Represents a Kafka message."""
key: Optional[str]
value: Dict[str, Any]
topic: str
partition: Optional[int] = None
timestamp: Optional[datetime] = None
headers: Dict[str, str] = field(default_factory=dict)
def to_json(self) -> str:
return json.dumps(self.value)
@classmethod
def from_kafka_message(cls, msg) -> "Message":
return cls(
key=msg.key().decode() if msg.key() else None,
value=json.loads(msg.value().decode()),
topic=msg.topic(),
partition=msg.partition(),
timestamp=datetime.fromtimestamp(msg.timestamp()[1] / 1000),
headers={h[0]: h[1].decode() for h in (msg.headers() or [])}
)
# ==================== Producer ====================
class KafkaProducer:
"""Production-ready Kafka producer."""
def __init__(
self,
kafka_config: KafkaConfig,
producer_config: ProducerConfig
):
config = {**kafka_config.to_dict(), **producer_config.to_dict()}
self.producer = Producer(config)
self._delivery_callbacks: Dict[str, Callable] = {}
def _delivery_callback(self, err, msg):
"""Handle delivery reports."""
if err:
logger.error(f"Message delivery failed: {err}")
else:
MESSAGES_PRODUCED.labels(topic=msg.topic()).inc()
logger.debug(f"Message delivered to {msg.topic()}[{msg.partition()}]")
def produce(
self,
topic: str,
value: Dict[str, Any],
key: Optional[str] = None,
headers: Optional[Dict[str, str]] = None,
partition: Optional[int] = None,
callback: Optional[Callable] = None
):
"""Produce a message to Kafka."""
try:
kafka_headers = [(k, v.encode()) for k, v in (headers or {}).items()]
self.producer.produce(
topic=topic,
key=key.encode() if key else None,
value=json.dumps(value).encode(),
partition=partition,
headers=kafka_headers,
callback=callback or self._delivery_callback
)
# Trigger delivery reports
self.producer.poll(0)
except BufferError:
logger.warning("Producer buffer full, waiting...")
self.producer.poll(1)
self.produce(topic, value, key, headers, partition, callback)
def produce_batch(
self,
topic: str,
messages: List[Dict[str, Any]],
key_func: Optional[Callable] = None
):
"""Produce a batch of messages."""
for msg in messages:
key = key_func(msg) if key_func else None
self.produce(topic, msg, key)
self.flush()
def flush(self, timeout: float = 10.0):
"""Flush all pending messages."""
remaining = self.producer.flush(timeout)
if remaining > 0:
logger.warning(f"{remaining} messages still in queue after flush")
def close(self):
"""Close the producer."""
self.flush()
# ==================== Consumer ====================
class KafkaConsumer:
"""Production-ready Kafka consumer."""
def __init__(
self,
kafka_config: KafkaConfig,
consumer_config: ConsumerConfig,
topics: List[str]
):
config = {**kafka_config.to_dict(), **consumer_config.to_dict()}
self.consumer = Consumer(config)
self.topics = topics
self.consumer_config = consumer_config
self._running = False
self._handlers: Dict[str, Callable] = {}
def register_handler(self, topic: str, handler: Callable):
"""Register a message handler for a topic."""
self._handlers[topic] = handler
def start(self):
"""Start consuming messages."""
self.consumer.subscribe(self.topics)
self._running = True
logger.info(f"Consumer started for topics: {self.topics}")
while self._running:
try:
msg = self.consumer.poll(timeout=1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
continue
else:
raise KafkaException(msg.error())
# Process message
self._process_message(msg)
except Exception as e:
logger.error(f"Consumer error: {e}")
time.sleep(1)
def _process_message(self, kafka_msg):
"""Process a single message."""
topic = kafka_msg.topic()
with PROCESSING_TIME.labels(topic=topic).time():
try:
message = Message.from_kafka_message(kafka_msg)
handler = self._handlers.get(topic)
if handler:
handler(message)
# Commit offset after successful processing
self.consumer.commit(asynchronous=False)
MESSAGES_CONSUMED.labels(
topic=topic,
consumer_group=self.consumer_config.group_id
).inc()
except Exception as e:
logger.error(f"Error processing message: {e}")
# Implement dead letter queue or retry logic here
raise
def stop(self):
"""Stop the consumer."""
self._running = False
self.consumer.close()
logger.info("Consumer stopped")
# ==================== Stream Processor ====================
class StreamProcessor(ABC):
"""Base class for stream processors."""
@abstractmethod
def process(self, message: Message) -> Optional[Message]:
"""Process a message and optionally return output."""
pass
class FilterProcessor(StreamProcessor):
"""Filter messages based on predicate."""
def __init__(self, predicate: Callable[[Message], bool]):
self.predicate = predicate
def process(self, message: Message) -> Optional[Message]:
if self.predicate(message):
return message
return None
class TransformProcessor(StreamProcessor):
"""Transform message values."""
def __init__(self, transform_func: Callable[[Dict], Dict]):
self.transform_func = transform_func
def process(self, message: Message) -> Optional[Message]:
transformed_value = self.transform_func(message.value)
return Message(
key=message.key,
value=transformed_value,
topic=message.topic,
headers=message.headers
)
class AggregationProcessor(StreamProcessor):
"""Aggregate messages over time windows."""
def __init__(
self,
key_func: Callable[[Message], str],
agg_func: Callable[[List[Dict]], Dict],
window_seconds: int = 60
):
self.key_func = key_func
self.agg_func = agg_func
self.window_seconds = window_seconds
self.windows: Dict[str, List[Dict]] = defaultdict(list)
self.window_starts: Dict[str, datetime] = {}
self._lock = threading.Lock()
def process(self, message: Message) -> Optional[Message]:
key = self.key_func(message)
now = datetime.utcnow()
with self._lock:
# Check if window expired
if key in self.window_starts:
window_start = self.window_starts[key]
if (now - window_start).total_seconds() >= self.window_seconds:
# Emit aggregation
result = self._emit_window(key)
self.windows[key] = [message.value]
self.window_starts[key] = now
return result
else:
self.window_starts[key] = now
self.windows[key].append(message.value)
return None
def _emit_window(self, key: str) -> Message:
"""Emit aggregated window."""
values = self.windows[key]
aggregated = self.agg_func(values)
return Message(
key=key,
value=aggregated,
topic="aggregated",
headers={"window_size": str(len(values))}
)
# ==================== Streaming Pipeline ====================
class StreamingPipeline:
"""Orchestrates streaming data pipeline."""
def __init__(
self,
kafka_config: KafkaConfig,
consumer_config: ConsumerConfig,
producer_config: ProducerConfig
):
self.kafka_config = kafka_config
self.consumer_config = consumer_config
self.producer_config = producer_config
self.processors: List[StreamProcessor] = []
self.consumer: Optional[KafkaConsumer] = None
self.producer: Optional[KafkaProducer] = None
self.output_topic: Optional[str] = None
def add_processor(self, processor: StreamProcessor) -> "StreamingPipeline":
"""Add a processor to the pipeline."""
self.processors.append(processor)
return self
def set_output_topic(self, topic: str) -> "StreamingPipeline":
"""Set the output topic for processed messages."""
self.output_topic = topic
return self
def _process_message(self, message: Message):
"""Process message through all processors."""
current = message
for processor in self.processors:
if current is None:
break
current = processor.process(current)
if current and self.output_topic and self.producer:
self.producer.produce(
topic=self.output_topic,
value=current.value,
key=current.key,
headers=current.headers
)
def run(self, input_topics: List[str]):
"""Run the streaming pipeline."""
self.consumer = KafkaConsumer(
self.kafka_config,
self.consumer_config,
input_topics
)
self.producer = KafkaProducer(
self.kafka_config,
self.producer_config
)
for topic in input_topics:
self.consumer.register_handler(topic, self._process_message)
try:
self.consumer.start()
finally:
if self.producer:
self.producer.close()
# ==================== Dead Letter Queue ====================
class DeadLetterQueue:
"""Handle failed messages."""
def __init__(
self,
producer: KafkaProducer,
dlq_topic: str,
max_retries: int = 3
):
self.producer = producer
self.dlq_topic = dlq_topic
self.max_retries = max_retries
def send_to_dlq(
self,
message: Message,
error: Exception,
retry_count: int
):
"""Send failed message to DLQ."""
dlq_message = {
"original_topic": message.topic,
"original_key": message.key,
"original_value": message.value,
"error": str(error),
"error_type": type(error).__name__,
"retry_count": retry_count,
"timestamp": datetime.utcnow().isoformat()
}
self.producer.produce(
topic=self.dlq_topic,
value=dlq_message,
key=message.key,
headers={"original_topic": message.topic}
)
logger.warning(f"Message sent to DLQ: {message.key}")
# ==================== Topic Management ====================
class TopicManager:
"""Manage Kafka topics."""
def __init__(self, kafka_config: KafkaConfig):
self.admin = AdminClient(kafka_config.to_dict())
def create_topic(
self,
name: str,
num_partitions: int = 3,
replication_factor: int = 3,
config: Optional[Dict[str, str]] = None
):
"""Create a new topic."""
topic = NewTopic(
name,
num_partitions=num_partitions,
replication_factor=replication_factor,
config=config or {}
)
futures = self.admin.create_topics([topic])
for topic_name, future in futures.items():
try:
future.result()
logger.info(f"Created topic: {topic_name}")
except Exception as e:
logger.error(f"Failed to create topic {topic_name}: {e}")
def list_topics(self) -> List[str]:
"""List all topics."""
metadata = self.admin.list_topics()
return list(metadata.topics.keys())
# ==================== Example Usage ====================
def run_streaming_pipeline():
"""Example streaming pipeline execution."""
kafka_config = KafkaConfig(
bootstrap_servers="localhost:9092"
)
consumer_config = ConsumerConfig(
group_id="event-processor",
auto_offset_reset="earliest",
enable_auto_commit=False
)
producer_config = ProducerConfig(
acks="all",
enable_idempotence=True
)
# Create pipeline
pipeline = StreamingPipeline(
kafka_config,
consumer_config,
producer_config
)
# Add processors
pipeline.add_processor(
FilterProcessor(
predicate=lambda m: m.value.get("event_type") == "purchase"
)
)
pipeline.add_processor(
TransformProcessor(
transform_func=lambda v: {
**v,
"processed_at": datetime.utcnow().isoformat(),
"amount_usd": v.get("amount", 0) * 1.0 # Currency conversion
}
)
)
pipeline.set_output_topic("processed-events")
# Run pipeline
pipeline.run(["raw-events"])
if __name__ == "__main__":
run_streaming_pipeline()Stream Processing with Windowing
Windowing enables aggregations over bounded time intervals in unbounded streams. Tumbling windows divide time into fixed, non-overlapping intervals—useful for periodic reporting. Sliding windows overlap, providing smoother aggregations for monitoring and alerting. Session windows group events by activity periods, ideal for user behavior analysis.
Late data handling addresses the reality that events may arrive after their window closes. Watermarks track event-time progress, triggering window computations when sufficient data arrives. Configure allowed lateness to balance completeness against latency. Implement side outputs for late data that arrives after window finalization.
State management in stream processing requires careful attention to fault tolerance and scalability. Checkpoint state periodically to enable recovery from failures. Use incremental checkpointing for large state to minimize checkpoint duration. Design state schemas for evolution as processing logic changes over time.
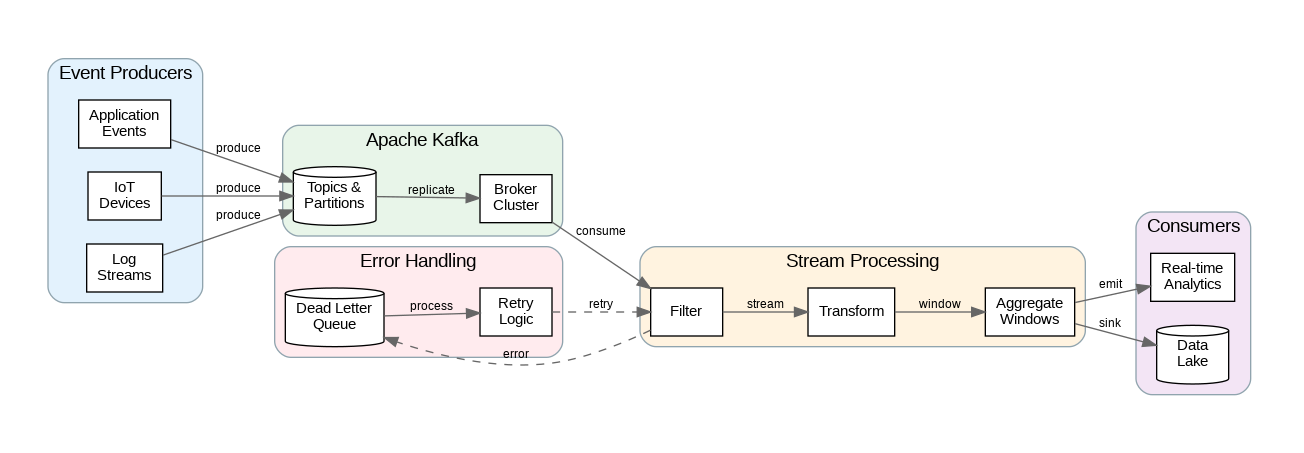
Key Takeaways and Best Practices
Real-time streaming enables immediate data processing but requires careful attention to delivery guarantees, state management, and failure handling. Design producers for idempotence and consumers for exactly-once processing where required. Implement dead letter queues for graceful error handling. Monitor consumer lag and processing latency to ensure pipeline health.
The code examples provided here establish patterns for production streaming systems. Start with simple event pipelines, then add stream processing as requirements evolve. In the next article, we’ll explore model deployment patterns, completing our journey from data engineering through MLOps to production ML systems.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.