Introduction: Natural language to SQL is one of the most practical LLM applications. Business users can query databases without knowing SQL, analysts can explore data faster, and developers can prototype queries quickly. But naive implementations fail spectacularly—generating invalid SQL, hallucinating table names, or producing queries that return wrong results. This guide covers building robust text-to-SQL systems: providing schema context effectively, validating generated SQL, handling errors gracefully, and implementing safety guardrails to prevent destructive queries.
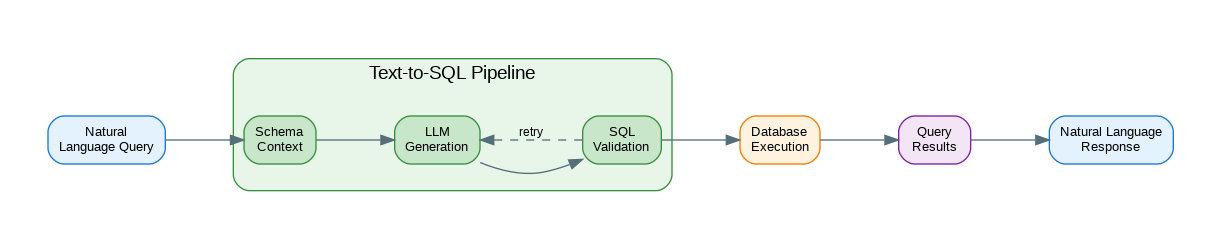
Basic Text-to-SQL
from openai import OpenAI
import sqlite3
client = OpenAI()
def get_schema_string(conn: sqlite3.Connection) -> str:
"""Extract schema from SQLite database."""
cursor = conn.execute(
"SELECT sql FROM sqlite_master WHERE type='table' AND sql IS NOT NULL"
)
schemas = []
for row in cursor:
schemas.append(row[0])
return "\n\n".join(schemas)
def text_to_sql(question: str, schema: str) -> str:
"""Convert natural language to SQL."""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": f"""You are a SQL expert. Convert natural language questions to SQL queries.
Database schema:
{schema}
Rules:
- Return ONLY the SQL query, no explanation
- Use only tables and columns that exist in the schema
- Use appropriate JOINs when needed
- Handle NULL values appropriately
- Use aliases for readability"""
},
{"role": "user", "content": question}
],
temperature=0
)
sql = response.choices[0].message.content.strip()
# Remove markdown code blocks if present
if sql.startswith("```"):
sql = sql.split("\n", 1)[1]
sql = sql.rsplit("```", 1)[0]
return sql.strip()
def execute_query(conn: sqlite3.Connection, sql: str) -> list[dict]:
"""Execute SQL and return results as list of dicts."""
cursor = conn.execute(sql)
columns = [desc[0] for desc in cursor.description]
results = []
for row in cursor:
results.append(dict(zip(columns, row)))
return results
def ask_database(conn: sqlite3.Connection, question: str) -> dict:
"""Full pipeline: question -> SQL -> results."""
schema = get_schema_string(conn)
sql = text_to_sql(question, schema)
try:
results = execute_query(conn, sql)
return {
"success": True,
"sql": sql,
"results": results,
"row_count": len(results)
}
except Exception as e:
return {
"success": False,
"sql": sql,
"error": str(e)
}
# Usage
conn = sqlite3.connect("sales.db")
result = ask_database(conn, "What were total sales by product category last month?")
print(f"SQL: {result['sql']}")
print(f"Results: {result['results']}")Schema Context Optimization
from dataclasses import dataclass
@dataclass
class TableInfo:
name: str
columns: list[dict] # {"name": str, "type": str, "description": str}
sample_values: dict[str, list] # column -> sample values
row_count: int
def get_enhanced_schema(conn: sqlite3.Connection) -> list[TableInfo]:
"""Get schema with sample values and descriptions."""
tables = []
# Get table names
cursor = conn.execute(
"SELECT name FROM sqlite_master WHERE type='table'"
)
table_names = [row[0] for row in cursor]
for table_name in table_names:
# Get columns
cursor = conn.execute(f"PRAGMA table_info({table_name})")
columns = []
for row in cursor:
columns.append({
"name": row[1],
"type": row[2],
"nullable": not row[3],
"primary_key": bool(row[5])
})
# Get sample values
sample_values = {}
for col in columns:
cursor = conn.execute(
f"SELECT DISTINCT {col['name']} FROM {table_name} LIMIT 5"
)
sample_values[col['name']] = [row[0] for row in cursor]
# Get row count
cursor = conn.execute(f"SELECT COUNT(*) FROM {table_name}")
row_count = cursor.fetchone()[0]
tables.append(TableInfo(
name=table_name,
columns=columns,
sample_values=sample_values,
row_count=row_count
))
return tables
def format_schema_for_llm(tables: list[TableInfo]) -> str:
"""Format schema optimally for LLM context."""
lines = []
for table in tables:
lines.append(f"Table: {table.name} ({table.row_count:,} rows)")
lines.append("Columns:")
for col in table.columns:
pk = " [PK]" if col.get("primary_key") else ""
samples = table.sample_values.get(col["name"], [])
sample_str = f" (e.g., {', '.join(repr(s) for s in samples[:3])})" if samples else ""
lines.append(f" - {col['name']}: {col['type']}{pk}{sample_str}")
lines.append("")
return "\n".join(lines)
# Selective schema for large databases
def get_relevant_tables(question: str, all_tables: list[TableInfo]) -> list[TableInfo]:
"""Select only relevant tables for the question."""
# Use LLM to identify relevant tables
table_list = "\n".join(f"- {t.name}: columns {[c['name'] for c in t.columns]}" for t in all_tables)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": f"""Given a question and list of tables, identify which tables are needed.
Tables:
{table_list}
Return only table names, comma-separated."""
},
{"role": "user", "content": question}
],
temperature=0
)
relevant_names = [n.strip() for n in response.choices[0].message.content.split(",")]
return [t for t in all_tables if t.name in relevant_names]SQL Validation and Error Recovery
import sqlparse
from typing import Optional
class SQLValidator:
"""Validate and sanitize generated SQL."""
DANGEROUS_KEYWORDS = [
"DROP", "DELETE", "TRUNCATE", "UPDATE", "INSERT",
"ALTER", "CREATE", "GRANT", "REVOKE", "EXEC"
]
def __init__(self, allow_writes: bool = False):
self.allow_writes = allow_writes
def validate(self, sql: str) -> tuple[bool, Optional[str]]:
"""Validate SQL. Returns (is_valid, error_message)."""
# Parse SQL
try:
parsed = sqlparse.parse(sql)
if not parsed:
return False, "Could not parse SQL"
except Exception as e:
return False, f"Parse error: {e}"
# Check for dangerous operations
if not self.allow_writes:
sql_upper = sql.upper()
for keyword in self.DANGEROUS_KEYWORDS:
if keyword in sql_upper:
return False, f"Dangerous operation not allowed: {keyword}"
# Check for multiple statements
if len(parsed) > 1:
return False, "Multiple statements not allowed"
# Check statement type
stmt = parsed[0]
if stmt.get_type() not in ("SELECT", "UNKNOWN"):
if not self.allow_writes:
return False, f"Only SELECT queries allowed, got: {stmt.get_type()}"
return True, None
def sanitize(self, sql: str) -> str:
"""Sanitize SQL query."""
# Remove comments
sql = sqlparse.format(sql, strip_comments=True)
# Normalize whitespace
sql = sqlparse.format(sql, reindent=True)
# Remove trailing semicolons
sql = sql.rstrip(";")
return sql
def text_to_sql_with_validation(
question: str,
schema: str,
conn: sqlite3.Connection,
max_retries: int = 3
) -> dict:
"""Generate SQL with validation and error recovery."""
validator = SQLValidator(allow_writes=False)
messages = [
{
"role": "system",
"content": f"""You are a SQL expert. Convert questions to SQL.
Schema:
{schema}
Return ONLY valid SQL. No explanations."""
},
{"role": "user", "content": question}
]
for attempt in range(max_retries):
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0
)
sql = response.choices[0].message.content.strip()
# Remove code blocks
if "```" in sql:
sql = sql.split("```")[1]
if sql.startswith("sql"):
sql = sql[3:]
sql = sql.strip()
# Validate
is_valid, error = validator.validate(sql)
if not is_valid:
messages.append({"role": "assistant", "content": sql})
messages.append({
"role": "user",
"content": f"Error: {error}. Please fix the SQL."
})
continue
# Try to execute
try:
sql = validator.sanitize(sql)
cursor = conn.execute(sql)
columns = [desc[0] for desc in cursor.description]
results = [dict(zip(columns, row)) for row in cursor]
return {
"success": True,
"sql": sql,
"results": results,
"attempts": attempt + 1
}
except Exception as e:
messages.append({"role": "assistant", "content": sql})
messages.append({
"role": "user",
"content": f"SQL execution error: {e}. Please fix."
})
return {
"success": False,
"sql": sql,
"error": "Max retries exceeded"
}Natural Language Response
def generate_natural_response(
question: str,
sql: str,
results: list[dict]
) -> str:
"""Convert SQL results to natural language."""
# Truncate results for context
results_str = str(results[:20])
if len(results) > 20:
results_str += f"\n... and {len(results) - 20} more rows"
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": """Convert SQL query results into a natural language answer.
Be concise but complete. Include specific numbers and data points.
If results are empty, say so clearly."""
},
{
"role": "user",
"content": f"""Question: {question}
SQL executed: {sql}
Results: {results_str}
Provide a natural language answer:"""
}
]
)
return response.choices[0].message.content
def full_text_to_sql_pipeline(
conn: sqlite3.Connection,
question: str
) -> dict:
"""Complete pipeline with natural language response."""
schema = get_schema_string(conn)
# Generate and execute SQL
result = text_to_sql_with_validation(question, schema, conn)
if not result["success"]:
return {
"answer": f"I couldn't answer that question. Error: {result.get('error', 'Unknown')}",
"sql": result.get("sql"),
"success": False
}
# Generate natural response
answer = generate_natural_response(
question,
result["sql"],
result["results"]
)
return {
"answer": answer,
"sql": result["sql"],
"results": result["results"],
"success": True
}
# Usage
result = full_text_to_sql_pipeline(
conn,
"Which products had the highest sales growth compared to last year?"
)
print(f"Answer: {result['answer']}")
print(f"SQL: {result['sql']}")Production Text-to-SQL Service
from dataclasses import dataclass
from typing import Optional
import hashlib
import json
@dataclass
class QueryResult:
question: str
sql: str
results: list[dict]
answer: str
execution_time_ms: float
cached: bool
class TextToSQLService:
"""Production-ready text-to-SQL service."""
def __init__(
self,
conn: sqlite3.Connection,
cache_enabled: bool = True,
max_results: int = 1000,
timeout_seconds: int = 30
):
self.conn = conn
self.cache_enabled = cache_enabled
self.max_results = max_results
self.timeout = timeout_seconds
self.cache: dict[str, QueryResult] = {}
# Pre-load schema
self.schema = get_schema_string(conn)
self.tables = get_enhanced_schema(conn)
def _cache_key(self, question: str) -> str:
"""Generate cache key for question."""
return hashlib.md5(question.lower().strip().encode()).hexdigest()
def query(self, question: str, use_cache: bool = True) -> QueryResult:
"""Execute text-to-SQL query."""
import time
start = time.time()
# Check cache
cache_key = self._cache_key(question)
if use_cache and self.cache_enabled and cache_key in self.cache:
cached = self.cache[cache_key]
return QueryResult(
question=question,
sql=cached.sql,
results=cached.results,
answer=cached.answer,
execution_time_ms=(time.time() - start) * 1000,
cached=True
)
# Get relevant schema
relevant_tables = get_relevant_tables(question, self.tables)
schema = format_schema_for_llm(relevant_tables)
# Generate SQL
result = text_to_sql_with_validation(question, schema, self.conn)
if not result["success"]:
raise ValueError(f"Query failed: {result.get('error')}")
# Limit results
results = result["results"][:self.max_results]
# Generate answer
answer = generate_natural_response(question, result["sql"], results)
query_result = QueryResult(
question=question,
sql=result["sql"],
results=results,
answer=answer,
execution_time_ms=(time.time() - start) * 1000,
cached=False
)
# Cache result
if self.cache_enabled:
self.cache[cache_key] = query_result
return query_result
def explain_sql(self, sql: str) -> str:
"""Explain what a SQL query does."""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "Explain SQL queries in simple terms for non-technical users."
},
{"role": "user", "content": f"Explain this SQL:\n{sql}"}
]
)
return response.choices[0].message.content
# FastAPI endpoint
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
app = FastAPI()
class QueryRequest(BaseModel):
question: str
use_cache: bool = True
class QueryResponse(BaseModel):
answer: str
sql: str
row_count: int
execution_time_ms: float
cached: bool
service = TextToSQLService(sqlite3.connect("database.db"))
@app.post("/query", response_model=QueryResponse)
async def query_database(request: QueryRequest):
try:
result = service.query(request.question, request.use_cache)
return QueryResponse(
answer=result.answer,
sql=result.sql,
row_count=len(result.results),
execution_time_ms=result.execution_time_ms,
cached=result.cached
)
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))References
- LangChain SQL: https://python.langchain.com/docs/use_cases/sql/
- Vanna AI: https://vanna.ai/
- SQLCoder: https://github.com/defog-ai/sqlcoder
- Spider Benchmark: https://yale-lily.github.io/spider
Conclusion
Text-to-SQL democratizes data access, letting anyone query databases using natural language. The key to success is providing rich schema context—table names, column types, sample values, and relationships. Always validate generated SQL before execution, both for correctness and safety. Implement retry logic with error feedback to recover from generation mistakes. Add natural language response generation to make results accessible to non-technical users. For production systems, cache common queries, limit result sizes, and implement proper timeout handling. Start with a focused domain (one database, specific question types) and expand gradually. The technology is mature enough for production use, but requires careful engineering to handle edge cases and ensure reliability.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.