After two decades of building data platforms, I’ve witnessed the pendulum swing between data lakes and data warehouses multiple times. Organizations would invest heavily in one approach, hit its limitations, then pivot to the other. The data lakehouse architecture represents something different—a genuine synthesis that addresses the fundamental trade-offs that forced us to choose between these paradigms in the first place.
The Problem with Traditional Approaches
Data warehouses excel at structured analytics but struggle with unstructured data, real-time ingestion, and the cost of storing massive datasets. Data lakes handle scale and variety but lack the ACID transactions, schema enforcement, and query performance that business users expect. Most enterprises ended up running both, creating data silos, governance nightmares, and the infamous “data swamp” problem where raw data becomes unusable without extensive curation.
The lakehouse architecture solves this by bringing warehouse-like capabilities directly to data lake storage. The key innovation is the open table format—Delta Lake, Apache Iceberg, or Apache Hudi—that adds a metadata layer on top of Parquet files, enabling ACID transactions, time travel, and schema evolution while maintaining the cost efficiency and openness of object storage.
The Medallion Architecture: Bronze, Silver, Gold
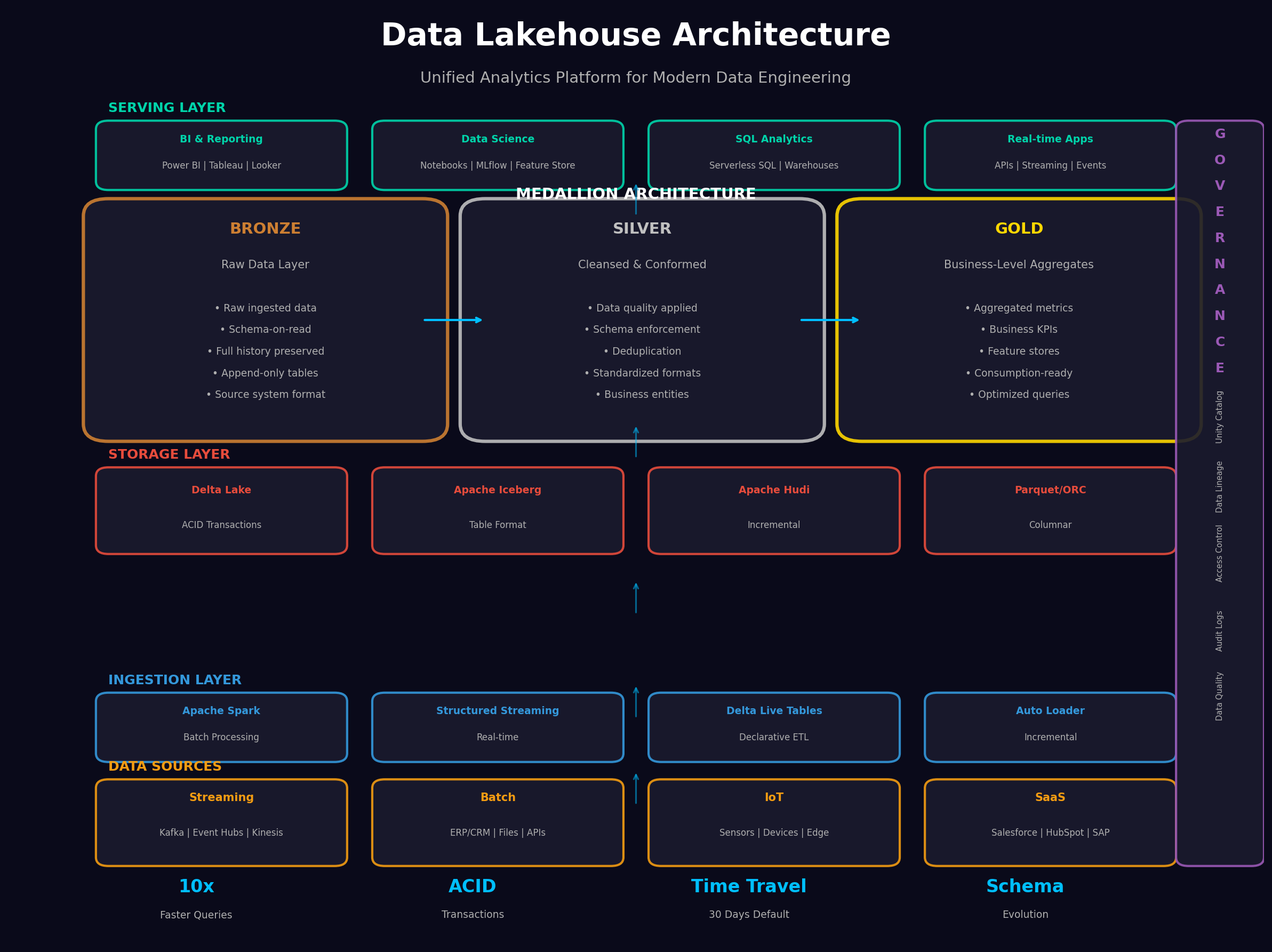
The medallion architecture has become the standard pattern for organizing data in a lakehouse. It’s not just a naming convention—it represents a fundamental approach to data quality and governance that I’ve found essential in production systems.
Bronze Layer: Raw data lands here exactly as it arrives from source systems. No transformations, no filtering—just append-only ingestion with full history preserved. This layer serves as your system of record and enables replay of any transformation pipeline. Schema-on-read applies here, allowing you to ingest data before fully understanding its structure.
Silver Layer: This is where data engineering happens. Deduplication, data quality rules, schema enforcement, and standardization transform raw data into clean, conformed datasets. Business entities emerge here—customers, products, transactions—with consistent definitions across the organization. The silver layer is your single source of truth for operational reporting.
Gold Layer: Business-level aggregates and feature stores live here. These are consumption-ready datasets optimized for specific use cases—executive dashboards, machine learning features, or domain-specific data products. Query performance is paramount, so you’ll often see denormalization and pre-aggregation at this layer.
When to Use What: Platform Selection
Databricks: The original lakehouse platform, built around Delta Lake. Best for organizations heavily invested in Apache Spark, needing advanced ML capabilities, or requiring the most mature Delta Lake implementation. The Unity Catalog provides excellent governance. Cost: Premium pricing but strong TCO for complex workloads.
Snowflake: Now supports Iceberg tables, bringing lakehouse capabilities to their cloud data warehouse. Ideal if you’re already a Snowflake customer or prefer SQL-first analytics. The separation of storage and compute is excellent for variable workloads. Cost: Consumption-based, can be expensive for always-on workloads.
AWS Lake Formation + Athena: Native AWS solution using Iceberg or Hudi. Best for AWS-centric organizations wanting tight integration with the broader AWS ecosystem. Serverless query execution keeps costs low for intermittent workloads. Cost: Pay-per-query model works well for exploratory analytics.
Azure Synapse + OneLake: Microsoft’s unified analytics platform with Delta Lake support. Ideal for organizations using Power BI and the Microsoft ecosystem. The integration with Azure Machine Learning and Purview governance is seamless. Cost: Competitive for mixed workloads.
Google BigQuery + BigLake: Brings lakehouse capabilities to BigQuery with support for Iceberg tables. Best for organizations already using BigQuery or needing strong integration with Vertex AI. Cost: Slot-based pricing provides predictability.
Implementation Lessons from Production
After implementing lakehouse architectures across multiple enterprises, several patterns have proven essential. First, invest heavily in data quality at the silver layer—garbage in, garbage out applies regardless of how sophisticated your architecture is. Implement data contracts between producers and consumers, and fail fast when contracts are violated.
Second, don’t underestimate the importance of table maintenance. Delta Lake’s OPTIMIZE and VACUUM commands, Iceberg’s compaction, and Hudi’s clustering are not optional—they’re essential for query performance. Build these into your pipelines from day one.
Third, embrace incremental processing. The days of nightly batch jobs that reprocess entire datasets are over. Change data capture, merge operations, and streaming ingestion should be your default patterns. This reduces costs, improves freshness, and makes your pipelines more resilient.
The Governance Imperative
A lakehouse without governance is just a more expensive data swamp. Unity Catalog, AWS Lake Formation, or Purview aren’t nice-to-haves—they’re foundational. Implement column-level security, data lineage tracking, and access auditing from the start. The open table formats make this easier than ever, but it still requires intentional design.
The lakehouse architecture represents the maturation of the modern data stack. It’s not about choosing between lakes and warehouses anymore—it’s about building unified platforms that serve the full spectrum of analytics needs while maintaining the governance and reliability that enterprises require.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.