Introduction
If you’ve spent time designing SaaS applications on AWS, you’ve lived this problem. You want the operational simplicity of a single Lambda function handling all tenant requests. But your security and compliance teams want guarantees that Tenant A’s data cannot be accessed by Tenant B’s invocation — not through application bugs, not through environmental reuse, not through any pathway. These requirements have historically been in tension, forcing architects to choose between a clean operational model and a defensible security posture.
AWS Lambda Tenant Isolation Mode, launched in November 2025 and reaching production readiness in early 2026, resolves this tension at the platform level. It provides hardware-level isolation between tenant execution environments — using the same Firecracker MicroVM technology that already isolates Lambda functions from each other — without requiring you to deploy or manage separate functions per tenant. One function. Isolated execution environments. Zero cross-tenant environment reuse.
This article examines the feature in technical depth: how Firecracker isolation actually works, what tenant isolation mode adds to the existing security model, how to implement it correctly, what the cold-start implications are in production, how to structure a fully compliant multi-tenant architecture using the feature alongside application-level data controls, and what HIPAA, PCI-DSS, and SOC 2 auditors will and will not accept about the feature.
Why Multi-Tenant Lambda Has Always Felt Risky
The concern at the heart of multi-tenant Lambda security is execution environment reuse. AWS Lambda maintains a pool of warm execution environments — small Firecracker MicroVMs — to reduce cold-start latency. When a new request arrives for a function, the runtime preferentially routes it to a warm environment that recently handled a prior invocation. This is a core performance feature of Lambda. It is also the mechanism that creates multi-tenancy risk in shared functions.
In a shared multi-tenant Lambda function, Tenant A’s invocation may initialise a database connection, load secrets from Secrets Manager into memory, and write temporary data to /tmp. When that invocation completes, the environment returns to the warm pool. The next invocation routed to that environment — potentially Tenant B’s — starts with the same process context. Connection pools established for Tenant A’s database credentials are still alive. In-memory caches loaded during Tenant A’s initialisation are still present. /tmp files written by Tenant A are accessible.
Most well-written multi-tenant Lambda functions clear sensitive data between invocations. But “well-written” is not a compliance guarantee — it’s a developer discipline that cannot be enforced by policy, audited by tooling, or relied upon across all future code contributions. Enterprise SaaS customers increasingly demand contractual guarantees of compute isolation that transcend code review practices.
How Firecracker MicroVM Isolation Works
To understand what tenant isolation mode adds, you first need to understand what Firecracker already provides. Firecracker is the open-source Virtual Machine Monitor (VMM) that AWS built and open-sourced in 2018. It powers both Lambda and AWS Fargate. Every Lambda execution environment runs inside its own Firecracker MicroVM — a hardware-virtualised, minimal-footprint VM with a stripped-down kernel, no unnecessary devices, and a small (~125ms) boot time.
Firecracker MicroVMs provide strong isolation between different Lambda functions. Function A and Function B — even in the same AWS account — run in separate VMs with separate memory spaces, separate kernels, and no shared IPC mechanisms. This function-level isolation has been the security foundation of Lambda since its early adoption of Firecracker in 2018.
What Firecracker does not prevent, by itself, is environment reuse between invocations of the same function. That’s by design — environment reuse is the mechanism that delivers warm-start performance. Two consecutive invocations of the same Lambda function share a Firecracker MicroVM, including its process memory, file system state (/tmp), and open network connections. This is safe when all invocations belong to the same logical tenant, and potentially unsafe when they do not.
What Tenant Isolation Mode Adds to the Security Model
Lambda Tenant Isolation Mode extends the Firecracker isolation boundary downward from the function level to the individual tenant level. When tenant isolation is enabled, the Lambda runtime routes invocations to execution environments using the tenant identifier as a routing key. Environments that handled Tenant A’s invocations are only reused for subsequent Tenant A invocations. They are never offered to Tenant B’s invocations.
This is enforced at the runtime scheduling layer, outside your application code. There is no way to bypass it from inside the function handler. The guarantee is platform-level, not code-level — which is precisely what security auditors require.
/tmp filesystem content from Tenant A never visible to Tenant B in the same function. (3) In-memory global state and connection pools cannot cross tenant boundaries. (4) The same Firecracker MicroVM is never shared between different tenant IDs.Enabling Tenant Isolation: Step-by-Step Implementation
Tenant isolation mode is enabled at function configuration level and activated per-invocation via an identifier in the client context. Here is a complete implementation guide.
Function Configuration
# SAM template - enable tenant isolation at function level
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
MultiTenantProcessor:
Type: AWS::Serverless::Function
Properties:
FunctionName: tenant-isolated-processor
Handler: handler.process
Runtime: python3.13
Timeout: 30
MemorySize: 1024
Architectures: [arm64]
# Tenant isolation configuration
TenantIsolationConfig:
Mode: PerTenant # Each unique tenantId gets a dedicated execution environment
Environment:
Variables:
POWERTOOLS_SERVICE_NAME: multi-tenant-processor
LOG_LEVEL: INFO
Invoking with a Tenant Identifier
Every invocation must include the tenant identifier in the client context. AWS Lambda uses this field to enforce environment routing. If the tenant identifier is absent on a function with tenant isolation enabled, the invocation is rejected with a TenantIdentifierRequired error.
import boto3
import json
import base64
lambda_client = boto3.client("lambda", region_name="us-east-1")
def invoke_for_tenant(tenant_id: str, payload: dict, async_invoke: bool = False) -> dict:
"""
Invoke a tenant-isolated Lambda function.
The tenantId in client_context drives execution environment routing.
"""
if not tenant_id or len(tenant_id) > 128:
raise ValueError("tenant_id must be 1-128 characters")
# Client context must be base64-encoded JSON
client_context = base64.b64encode(json.dumps({
"custom": {
"tenantId": tenant_id # This is the routing key for isolation
}
}).encode("utf-8")).decode("utf-8")
invocation_type = "Event" if async_invoke else "RequestResponse"
response = lambda_client.invoke(
FunctionName="tenant-isolated-processor",
InvocationType=invocation_type,
ClientContext=client_context,
Payload=json.dumps(payload)
)
if async_invoke:
return {"status_code": response["StatusCode"]}
result = json.loads(response["Payload"].read())
if response.get("FunctionError"):
raise RuntimeError(f"Lambda error: {result}")
return result
# API Gateway Lambda Authorizer - extract and forward tenant ID
def authorizer_handler(event, context):
"""Lambda authorizer that validates JWT and extracts tenant ID"""
token = event.get("authorizationToken", "").replace("Bearer ", "")
claims = verify_jwt(token) # Your JWT validation logic
tenant_id = claims.get("custom:tenantId")
if not tenant_id:
raise Exception("Unauthorized") # Triggers 401
# Policy allows invocation; tenant_id is passed in context
# to be forwarded as client context by your API handler
return {
"principalId": claims["sub"],
"policyDocument": {
"Version": "2012-10-17",
"Statement": [{"Effect": "Allow", "Action": "execute-api:Invoke", "Resource": event["methodArn"]}]
},
"context": {"tenantId": tenant_id, "userId": claims["sub"]}
}
Inside the Function Handler: Accessing the Tenant Context
from aws_lambda_powertools import Logger
import base64, json, boto3
logger = Logger(service="multi-tenant-processor")
def process(event, context):
# Retrieve tenant ID from client context (injected by calling code)
client_ctx_raw = context.client_context
if not client_ctx_raw or "custom" not in client_ctx_raw:
raise ValueError("Missing tenant context")
tenant_id = client_ctx_raw["custom"]["tenantId"]
# Validate tenant_id against an allow-list in your tenant registry
if not is_valid_tenant(tenant_id):
logger.warning("Invalid tenant ID", tenant_id=tenant_id)
raise ValueError(f"Unknown tenant: {tenant_id}")
logger.append_keys(tenant_id=tenant_id)
logger.info("Processing request", event_keys=list(event.keys()))
# All downstream calls use tenant-scoped credentials/data paths
result = process_business_logic(event, tenant_id)
return {"tenant_id": tenant_id, "result": result}
def process_business_logic(event: dict, tenant_id: str) -> dict:
"""
Always scope data access by tenant_id, even though the execution
environment is already isolated. Defense in depth.
"""
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table("shared-orders-table")
# Partition key includes tenant_id - application-level data isolation
response = table.get_item(Key={
"PK": f"TENANT#{tenant_id}",
"SK": f"ORDER#{event['order_id']}"
})
return response.get("Item", {})
Production Architecture: Compliant Multi-Tenant SaaS on Serverless
flowchart TB
WAF["AWS WAF"] --> APIGW["API Gateway HTTP API"]
Cognito["Amazon Cognito"] --> APIGW
APIGW --> Auth["Lambda Authorizer - extract tenantId"]
Auth --> Fn["Lambda Function - Tenant Isolation Mode ENABLED"]
Fn --> EnvA["MicroVM: tenant-acme - Firecracker Isolated"]
Fn --> EnvB["MicroVM: tenant-globex - Firecracker Isolated"]
EnvA --> DDB["DynamoDB - PK: TENANT#id"]
EnvB --> DDB
EnvA --> SM["Secrets Manager - Per-tenant paths"]
EnvA --> KMS["AWS KMS - Per-tenant CMKs"]
EnvB --> SM
EnvB --> KMSCold Start Management: Tiered SaaS Architecture
The most significant operational trade-off introduced by tenant isolation mode is cold start behaviour. In a standard shared Lambda pool, execution environments are reused across all tenants — a warm environment that processed Tenant A’s request is just as useful for Tenant B’s next request. With tenant isolation, environments are tenant-specific. A warm environment for Tenant A cannot serve Tenant B’s cold start.
For a SaaS with 1,000 tenants and low per-tenant request frequencies, this can significantly increase the percentage of cold starts compared to a purely shared pool. The practical impact depends on your tenant activity distribution. High-activity tenants with frequent invocations will maintain warm environments naturally. Long-tail tenants with infrequent invocations will cold-start frequently.
The recommended production pattern is a tiered SaaS architecture that applies Provisioned Concurrency selectively based on tier:
import boto3
lambda_client = boto3.client("lambda")
# Tier-based Provisioned Concurrency configuration
TIER_CONFIG = {
"enterprise": {"provisioned_concurrency": 20},
"professional": {"provisioned_concurrency": 5},
"starter": {"provisioned_concurrency": 0}, # On-demand only
}
def configure_tenant_provisioning(tenant_id: str, tier: str):
"""
Apply provisioned concurrency at alias level for the function.
Higher-tier tenants get guaranteed warm environments.
Note: Provisioned Concurrency on a tenant-isolated function
pre-warms environments that are then assigned to tenants on first use.
"""
config = TIER_CONFIG.get(tier, {"provisioned_concurrency": 0})
if config["provisioned_concurrency"] > 0:
lambda_client.put_provisioned_concurrency_config(
FunctionName="tenant-isolated-processor",
Qualifier="prod",
ProvisionedConcurrentExecutions=config["provisioned_concurrency"]
)
# Record tier in tenant registry (DynamoDB)
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table("tenant-registry")
table.update_item(
Key={"tenant_id": tenant_id},
UpdateExpression="SET tier = :t, provisioned_concurrency = :pc",
ExpressionAttributeValues={":t": tier, ":pc": config["provisioned_concurrency"]}
)
Application-Level Data Isolation: Completing the Security Stack
Tenant isolation mode provides compute isolation — no shared execution environments. It does not provide data isolation. Your application still needs to ensure that database queries, cache accesses, and object storage operations are scoped to the correct tenant. Compute isolation and data isolation are complementary layers; neither is sufficient alone.
The recommended pattern for DynamoDB is a composite partition key that embeds the tenant identifier, ensuring that a query or scan for Tenant A’s partition key can never return Tenant B’s records:
import boto3
from boto3.dynamodb.conditions import Key
from botocore.exceptions import ClientError
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table("tenant-data")
class TenantDataService:
"""
All data access methods enforce tenant scoping at query level.
Even with compute isolation, application-level scoping is defense-in-depth.
"""
def __init__(self, tenant_id: str):
self.tenant_id = tenant_id
self.pk_prefix = f"TENANT#{tenant_id}"
def get_record(self, record_id: str) -> dict:
response = table.get_item(
Key={
"PK": self.pk_prefix,
"SK": f"RECORD#{record_id}"
}
)
item = response.get("Item")
# Double-check tenant ownership - belt and suspenders
if item and item.get("tenant_id") != self.tenant_id:
raise PermissionError(f"Record {record_id} does not belong to tenant {self.tenant_id}")
return item
def query_records(self, record_type: str, limit: int = 100) -> list:
response = table.query(
KeyConditionExpression=Key("PK").eq(self.pk_prefix) & Key("SK").begins_with(f"{record_type}#"),
Limit=limit
)
return response["Items"]
def put_record(self, record_id: str, data: dict) -> None:
table.put_item(
Item={
"PK": self.pk_prefix,
"SK": f"RECORD#{record_id}",
"tenant_id": self.tenant_id, # Explicit ownership attribute
**data
},
# Conditional write - prevent overwriting another tenant's record
ConditionExpression="attribute_not_exists(PK) OR tenant_id = :tid",
ExpressionAttributeValues={":tid": self.tenant_id}
)
Per-Tenant KMS Customer Managed Keys
For highly regulated workloads (HIPAA, PCI-DSS Level 1), consider provisioning a separate AWS KMS Customer Managed Key (CMK) per tenant. This allows tenants to independently audit key usage in CloudTrail, rotate their keys on demand, and revoke access by disabling the CMK without affecting other tenants. It is the gold standard for data-at-rest isolation in SaaS.
import boto3
kms = boto3.client("kms")
def provision_tenant_kms_key(tenant_id: str, tenant_name: str) -> str:
"""Create a dedicated KMS CMK for a new tenant at onboarding time."""
response = kms.create_key(
Description=f"Tenant encryption key: {tenant_name} ({tenant_id})",
KeyUsage="ENCRYPT_DECRYPT",
KeySpec="SYMMETRIC_DEFAULT",
Tags=[
{"TagKey": "tenant_id", "TagValue": tenant_id},
{"TagKey": "Environment", "TagValue": "production"},
{"TagKey": "ManagedBy", "TagValue": "tenant-onboarding-service"}
]
)
key_id = response["KeyMetadata"]["KeyId"]
# Create an alias for easy reference
kms.create_alias(
AliasName=f"alias/tenant/{tenant_id}",
TargetKeyId=key_id
)
# Enable automatic key rotation (annual)
kms.enable_key_rotation(KeyId=key_id)
return key_id
def encrypt_tenant_secret(tenant_id: str, plaintext: str) -> bytes:
"""Encrypt data using the tenant-specific CMK."""
response = kms.encrypt(
KeyId=f"alias/tenant/{tenant_id}",
Plaintext=plaintext.encode("utf-8"),
EncryptionContext={"tenant_id": tenant_id} # Bound to tenant context
)
return response["CiphertextBlob"]
HIPAA, PCI-DSS, and SOC 2: What Tenant Isolation Mode Covers — and What It Does Not
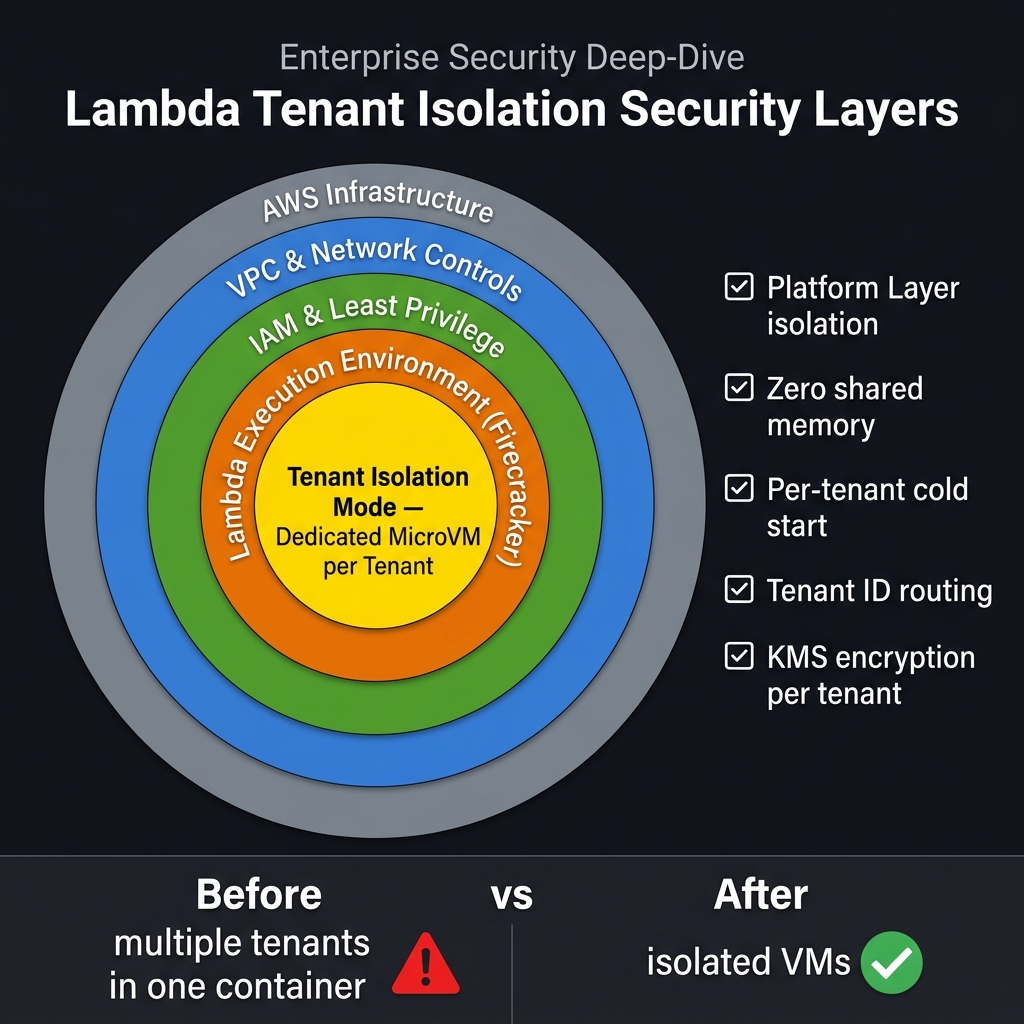
Enterprise SaaS architects frequently ask: does Lambda Tenant Isolation Mode satisfy the compute isolation requirements for HIPAA, PCI-DSS, or SOC 2? The answer is a qualified yes — for compute isolation specifically. Here is a precise breakdown of what the feature addresses and what complementary controls remain your responsibility.
Monitoring Tenant Behaviour with CloudWatch and AWS X-Ray
Observability in a tenant-isolated environment requires that every log entry, metric, and trace is tagged with the tenant identifier. This enables per-tenant dashboards, per-tenant error alerting, and forensic investigation if a security event is suspected.
from aws_lambda_powertools import Logger, Tracer, Metrics
from aws_lambda_powertools.metrics import MetricUnit
import boto3
logger = Logger(service="tenant-processor")
tracer = Tracer(service="tenant-processor")
metrics = Metrics(namespace="MultiTenantSaaS", service="tenant-processor")
@logger.inject_lambda_context
@tracer.capture_lambda_handler
@metrics.log_metrics(capture_cold_start_metric=True)
def process(event, context):
tenant_id = context.client_context["custom"]["tenantId"]
# Inject tenant_id into all subsequent log entries
logger.append_keys(tenant_id=tenant_id, tier=get_tenant_tier(tenant_id))
tracer.put_annotation(key="tenant_id", value=tenant_id)
# Emit per-tenant custom metrics
metrics.add_dimension(name="TenantId", value=tenant_id)
metrics.add_metric(name="RequestCount", unit=MetricUnit.Count, value=1)
try:
result = handle_request(event, tenant_id)
metrics.add_metric(name="SuccessCount", unit=MetricUnit.Count, value=1)
return result
except Exception as e:
metrics.add_metric(name="ErrorCount", unit=MetricUnit.Count, value=1)
logger.exception("Request failed", error=str(e))
raise
Key Takeaways
- Lambda Tenant Isolation Mode closes a decade-long gap in serverless multi-tenancy by providing platform-level, hardware-enforced per-tenant compute isolation via Firecracker MicroVMs — without requiring per-tenant function deployments
- The tenant identifier passed in client context is the platform routing key — it must be validated against your tenant registry inside the handler, never trusted blindly from the caller
- Cold start frequency increases with tenant isolation enabled; mitigate with tiered Provisioned Concurrency aligned to your SaaS pricing tiers
- Compute isolation is necessary but not sufficient — complement with DynamoDB composite partition keys, per-tenant KMS CMKs, scoped IAM roles, and per-tenant Secrets Manager paths
- For HIPAA, PCI-DSS, and SOC 2, the feature directly addresses compute isolation requirements; you retain responsibility for data-layer isolation, encryption, audit logging, and access management
- Tag every log entry, X-Ray trace, and CloudWatch metric with tenant_id from day one — retrofitting tenant-scoped observability is painful and forensically inadequate
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.