Introduction
AWS has had a productive 18 months. Between re:Invent 2025 and March 2026, the Lambda team shipped a cluster of releases that, individually, look like incremental improvements. Evaluated together, they constitute the most significant evolution of the serverless platform since Lambda’s launch. This is not another “top 10 features” recap. This is a technical walkthrough for architects and senior engineers who need to understand these changes deeply enough to redesign production systems around them.
We cover four capability areas: Lambda Managed Instances, which finally brings dedicated EC2 compute — including GPU — under the Lambda management model; SQS Provisioned Mode for Event Source Mappings, which eliminates the multi-minute scaling ramp that has made queue-driven Lambda impractical for latency-sensitive workloads; the 1 MB asynchronous payload expansion across Lambda, SQS, and EventBridge, which obsoletes the S3 claim-check pattern for the vast majority of event payloads; and .NET 10 and Node.js 24 runtime support, which makes ARM64/Graviton3 a first-class choice for every major enterprise language runtime.
Each section includes production-ready configuration, realistic cost analysis, and honest assessment of the limitations you need to plan around before committing architectural decisions.
Lambda Managed Instances: Dedicated Compute with Serverless Simplicity
The original Lambda constraint that most frustrated enterprise engineering teams was not the 15-minute timeout or the 10 GB memory limit. It was the compute model. Lambda’s shared execution pool is optimised for general-purpose CPU workloads. For teams running image processing pipelines, ML inference, document understanding, or cryptographic operations at scale — workloads that benefit from specific instance families, higher CPU-to-memory ratios, or GPU acceleration — Lambda was simply the wrong tool. The standard advice was “use ECS Fargate or EC2 for that.” Which meant managing a container orchestration layer, ECR image pipelines, cluster capacity planning, and losing Lambda’s per-request billing.
Lambda Managed Instances, launched at re:Invent 2025, changes this calculus. You configure a Lambda function to run on EC2 instances from your AWS account — specifying instance type, minimum and maximum fleet size, and optional dedicated tenancy. AWS continues to manage everything else: OS patching, security updates, load balancing across the instance fleet, auto-scaling within your configured bounds, and the Lambda runtime itself. Your function code and handler contract remain identical. You gain compute control without gaining operational overhead.
When to Use Lambda Managed Instances
GPU inference: ML models requiring GPU acceleration — image classification, embedding generation, real-time LLM inference with local models — can run as Lambda functions on G5 or G6 instances with NVIDIA A10G or L4 GPUs. The function scales to zero when idle (no idle GPU costs) and scales up on demand, unlike always-on GPU instances.
CPU-intensive batch processing: Document understanding, PDF parsing, video thumbnail extraction, and audio transcoding workloads benefit from high-CPU instance families (C7i, C7g) at a predictable per-invocation cost model rather than cluster-based per-hour billing.
High-memory workloads: Data transformations that require loading large reference datasets into memory — spatial indexing, in-memory graph operations, large embedding vector operations — can use R-family instances with high memory-to-CPU ratios not available in the standard Lambda execution pool.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
# GPU-backed Lambda for ML inference
MLInferenceFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: ml-inference-gpu
Handler: handler.infer
Runtime: python3.13
Timeout: 300
MemorySize: 16384 # Memory for model loading
ManagedInstanceConfig:
InstanceType: g5.2xlarge # 1x NVIDIA A10G GPU, 8 vCPU, 32 GB RAM
MinInstances: 1 # Keep at least one warm to avoid cold GPU init
MaxInstances: 10
Tenancy: shared # or "dedicated" for physical isolation
Environment:
Variables:
MODEL_PATH: /tmp/model # Model cached in /tmp after first load
CUDA_VISIBLE_DEVICES: "0"
# High-CPU instance for document processing
DocumentProcessorFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: document-processor
Handler: handler.process
Runtime: python3.13
Timeout: 120
ManagedInstanceConfig:
InstanceType: c7g.4xlarge # 16 vCPU ARM64 Graviton3 - excellent price/perf
MinInstances: 0 # Scale to zero when idle
MaxInstances: 50
Cost Analysis: Lambda Managed Instances vs. Always-On EC2
The economic case for Managed Instances is strongest for bursty, irregularly distributed workloads. Consider an ML inference workload averaging 2,000 requests/day, each taking 3 seconds on a GPU:
Always-on g5.2xlarge ($1.21/hour): $876/month regardless of actual load. At 2,000 requests × 3 seconds = 1.67 GPU-hours of actual work per day. You pay for 720 GPU-hours, use 50. Utilisation: 6.9%.
Lambda Managed Instances (g5.2xlarge, MinInstances: 0): Compute charges only during invocation duration. At 2,000 requests × 3 seconds, you consume 1.67 GPU-hours/day × $1.21/hour = ~$2.02/day = $60.60/month. Saving: ~$815/month — a 93% cost reduction for this workload profile.
The break-even point is approximately 40% GPU utilisation across the day. Above 40%, a provisioned EC2 instance becomes more cost-effective. Use this threshold to decide when to graduate from Managed Instances to a dedicated fleet.
MinInstances: 1 for GPU functions to avoid GPU driver initialisation cold starts (~30-60 seconds). The always-warm GPU instance cost (~$875/month for g5.2xlarge) is offset when you have more than ~60 GPU-hours of work per month — roughly 70,000 three-second inference requests.SQS Provisioned Mode for Event Source Mappings: Fixing the Burst Scaling Problem
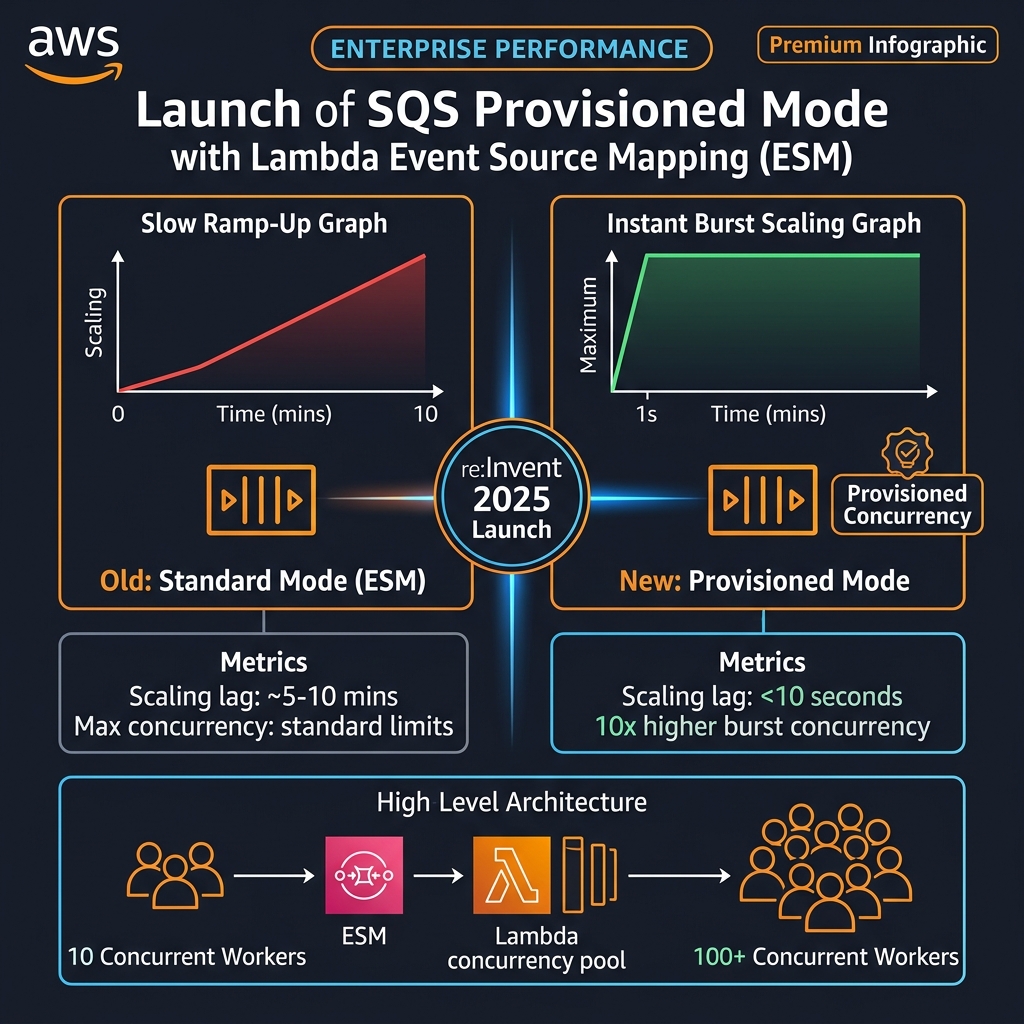
Lambda’s integration with SQS via Event Source Mappings has been a cornerstone of event-driven architectures for years. But it has carried a frustrating flaw for high-throughput, latency-sensitive systems: the burst scaling behaviour. When a queue accumulates a large backlog suddenly — a flash sale, a system recovery after an outage, a batch data pipeline arrival — the standard ESM scales Lambda concurrency gradually using a leaky-bucket algorithm. The first 60 seconds add 60 concurrent instances. Then 500 per minute. It can take 5-10 minutes to reach maximum concurrency.
For real-time financial transaction processing, time-sensitive IoT telemetry, or any workload where queue latency directly impacts business outcomes, this gradual ramp is architecturally unacceptable. Teams have worked around it with custom scaling solutions, SQS message pumping functions, pre-warming EventBridge rules, and other fragile hacks.
SQS Provisioned Mode for Event Source Mappings replaces the polling-based gradual ramp with a dedicated fleet of provisioned pollers. You specify a minimum and maximum poller count. The provisioned minimum pollers are always-warm and ready to dispatch messages immediately. When a burst occurs, the fleet scales to the maximum poller count within seconds, not minutes.
flowchart LR
subgraph Standard ["Standard ESM - Gradual Ramp"]
S1["Burst arrives"] --> S2["Minute 1: +60 concurrent"]
S2 --> S3["Minute 2: +500 concurrent"]
S3 --> S4["10+ min to full concurrency"]
S4 --> S5["Queue depth spikes, SLA breached"]
end
subgraph Provisioned ["Provisioned Mode ESM - Instant Scale"]
P1["Burst arrives"] --> P2["Provisioned pollers dispatch immediately"]
P2 --> P3["Full concurrency under 10 seconds"]
P3 --> P4["Queue drains in minutes"]
endimport boto3
lambda_client = boto3.client("lambda")
# Enable Provisioned Mode on a new Event Source Mapping
response = lambda_client.create_event_source_mapping(
FunctionName="arn:aws:lambda:us-east-1:123456789:function:transaction-processor",
EventSourceArn="arn:aws:sqs:us-east-1:123456789:transactions-queue",
# Batch configuration
BatchSize=100,
MaximumBatchingWindowInSeconds=5,
# Provisioned Mode - always-warm poller fleet
ProvisionedPollerConfig={
"MinimumPollers": 10, # Always-warm: handles steady-state with no scaling lag
"MaximumPollers": 500 # Burst ceiling - reached in seconds, not minutes
},
# Scaling ceiling for Lambda side
ScalingConfig={
"MaximumConcurrency": 1000 # Hard limit on Lambda concurrency
},
# Filter to reduce Lambda invocations for irrelevant messages
FilterCriteria={
"Filters": [
{"Pattern": '{"body": {"event_type": ["PAYMENT", "REFUND", "CHARGEBACK"]}}'}
]
}
)
print(f"ESM UUID: {response['UUID']}")
Real-World Configuration: Financial Transaction Pipeline
For a financial transaction processing pipeline handling 50,000 transactions/minute at peak with a 500ms SLA on queue processing, here is a production-grade Provisioned Mode ESM configuration:
# CDK - Provisioned Mode ESM for financial transactions
from aws_cdk import aws_lambda_event_sources as sources
from aws_cdk import aws_sqs as sqs
transaction_queue = sqs.Queue(
self, "TransactionQueue",
visibility_timeout=Duration.seconds(60),
# DLQ for failed messages after 3 attempts
dead_letter_queue=sqs.DeadLetterQueue(
max_receive_count=3,
queue=sqs.Queue(self, "TransactionDLQ",
retention_period=Duration.days(14))
)
)
transaction_fn.add_event_source(
sources.SqsEventSource(
transaction_queue,
batch_size=50,
max_batching_window=Duration.seconds(2),
# Provisioned Mode configuration
provisioned_poller_config=sources.ProvisionedPollerConfig(
minimum_pollers=20, # Pre-warmed for 50k/min steady state
maximum_pollers=2000 # Burst ceiling for flash sales
),
max_concurrency=5000,
# Report batch item failures for partial-batch success
report_batch_item_failures=True
)
)
The 1 MB Async Payload Limit: Ending the S3 Claim-Check Anti-Pattern
AWS increased the maximum payload size for asynchronous Lambda invocations, SQS messages, and EventBridge events from 256 KB to 1 MB. This is the change whose significance is most undersold in the official announcements. To understand why, you need to appreciate how pervasive the 256 KB limit has been as an architectural constraint.
Event-driven architectures frequently need to pass rich context between services: LLM prompts with full conversation history, medical records with associated metadata, financial transaction payloads with embedded audit trails, customer onboarding data with document contents. Most of these real-world payloads comfortably exceed 256 KB once serialised to JSON. For the past several years, the standard solution has been the S3 claim-check pattern: upload the payload to S3, pass only the S3 object key in the event, and have the downstream service download the payload from S3.
The claim-check pattern works, but it introduces: 2-3 additional S3 API calls per event (upload, presign/download, optionally delete); IAM complexity (every downstream service needs S3 read access to the payload bucket); lifecycle management (payload TTL, stuck workflow cleanup, cost monitoring on the payload bucket); and latency (~20-50ms for S3 put + get round-trips). At 10 million events/month, those S3 API calls add $4-8/month in direct API costs and compound latency at every event boundary in your pipeline.
# Before: The claim-check pattern (now unnecessary for payloads under 1 MB)
import boto3, json, uuid
s3 = boto3.client("s3")
events_client = boto3.client("events")
PAYLOAD_BUCKET = "my-event-payloads"
def publish_event_old(payload: dict, source: str, detail_type: str):
"""Old pattern: upload to S3 if payload too large."""
body = json.dumps(payload)
if len(body) > 200_000: # Safe margin under 256 KB limit
key = f"payloads/{uuid.uuid4()}.json"
s3.put_object(Bucket=PAYLOAD_BUCKET, Key=key, Body=body,
ContentType="application/json",
Expires=datetime.utcnow() + timedelta(hours=1))
event_detail = {"_s3_payload_key": key, "source": source}
else:
event_detail = payload
events_client.put_events(Entries=[{
"Source": source, "DetailType": detail_type,
"Detail": json.dumps(event_detail)
}])
# After: Direct embedding up to 1 MB, no S3 round-trip needed
def publish_event_new(payload: dict, source: str, detail_type: str):
"""New pattern: embed directly for payloads up to 1 MB."""
detail_json = json.dumps(payload)
if len(detail_json.encode("utf-8")) > 900_000: # Buffer below 1 MB limit
raise ValueError(f"Payload too large: {len(detail_json)} bytes")
events_client.put_events(Entries=[{
"Source": source, "DetailType": detail_type,
"Detail": detail_json # Direct embedding, no S3 intermediary
}])
_s3_payload_key field) during the transition. (3) Set S3 payload bucket lifecycle to expire objects after 7 days for cleanup. (4) Monitor for the 1 MB limit — payloads approaching it should be redesigned to pass pointers/IDs rather than full data..NET 10 and Node.js 24: Why Runtime Upgrades Matter More Than You Think
AWS Lambda now supports .NET 10 as a managed runtime and container base image, and Node.js 24 as a managed runtime. Runtime version announcements tend to get buried in the release notes, but for enterprise engineering teams these upgrades carry meaningful production implications.
.NET 10: Native AOT and the Cold Start Revolution
.NET has historically been the most penalised language runtime in serverless due to cold starts. A .NET 6 Lambda function on x86 cold-starting could take 800ms-1.5 seconds — unacceptable for synchronous API endpoints. .NET 8 improved this substantially with improved JIT and reduced runtime initialisation. .NET 10 on ARM64 with Native AOT compilation is a step change: cold starts under 50ms are routinely achievable for lightweight API handlers.
Native AOT compiles the .NET application ahead of time to native machine code during the build phase, eliminating the JIT compilation step at runtime startup. The resulting binary is a self-contained native executable — no .NET runtime installation required in the Lambda execution environment. The package size increases slightly (typically 20-35 MB for a compiled Lambda vs. 5-10 MB for a framework-dependent deployment), but the cold start and warm start performance improvements are substantial.
// .NET 10 Lambda with Native AOT - minimal API handler
// Build command: dotnet publish -c Release -r linux-arm64 --self-contained true
// Achieves <50ms cold start on arm64
using Amazon.Lambda.Core;
using Amazon.Lambda.APIGatewayEvents;
using System.Text.Json;
using System.Text.Json.Serialization;
// AOT requires source-generated JSON serialisation (no reflection)
[JsonSerializable(typeof(APIGatewayHttpApiV2ProxyRequest))]
[JsonSerializable(typeof(APIGatewayHttpApiV2ProxyResponse))]
[JsonSerializable(typeof(OrderResponse))]
public partial class LambdaSerializerContext : JsonSerializerContext { }
public class Function
{
private static readonly HttpClient _http = new(); // Reused across invocations
// [assembly: LambdaSerializer(typeof(SourceGeneratorLambdaJsonSerializer<LambdaSerializerContext>))]
public async Task<APIGatewayHttpApiV2ProxyResponse> Handler(
APIGatewayHttpApiV2ProxyRequest request,
ILambdaContext context)
{
context.Logger.LogInformation($"Cold start: {Environment.TickCount64}ms");
var orderId = request.PathParameters?["orderId"];
var order = await GetOrderAsync(orderId!);
return new APIGatewayHttpApiV2ProxyResponse
{
StatusCode = 200,
Body = JsonSerializer.Serialize(order, LambdaSerializerContext.Default.OrderResponse),
Headers = new Dictionary<string, string> { ["Content-Type"] = "application/json" }
};
}
private async Task<OrderResponse> GetOrderAsync(string orderId)
{
// DynamoDB call or downstream service invocation
return new OrderResponse { OrderId = orderId, Status = "fulfilled" };
}
}
public record OrderResponse
{
public string OrderId { get; init; } = "";
public string Status { get; init; } = "";
}
# SAM: .NET 10 Native AOT on ARM64
Resources:
OrderApi:
Type: AWS::Serverless::Function
Properties:
Runtime: dotnet10
Handler: bootstrap
Architectures: [arm64] # Graviton3 - 20% cheaper + faster
MemorySize: 512 # Native AOT runs lean, 512 MB is often sufficient
Timeout: 30
Metadata:
BuildMethod: dotnet-lambda-package
BuildProperties:
UseContainer: false
# Native AOT publish options
MSBuildParameters: >-
/p:PublishAot=true
/p:OptimizeSpeed=true
Node.js 24: V8 Engine Improvements and Import Map Support
Node.js 24 introduces V8 engine improvements that yield 5-12% faster warm invocation performance for CPU-bound JavaScript workloads. The more significant addition for Lambda use cases is stable import map support, which simplifies module resolution in complex TypeScript/ESM projects without bundler configuration, and the promotion of the fetch API to stable (no more node-fetch dependencies in Lambda packages).
// Node.js 24 Lambda handler - using native fetch (stable in Node 24)
// No more node-fetch or axios needed for simple HTTP calls
export const handler = async (event) => {
const tenantId = event.requestContext?.authorizer?.lambda?.tenantId;
// Native fetch - stable in Node.js 22+, improved performance in 24
const upstreamResponse = await fetch(
`${process.env.PRODUCTS_SERVICE_URL}/v2/products`,
{
method: "POST",
headers: {
"Content-Type": "application/json",
"X-Tenant-ID": tenantId,
"Authorization": `Bearer ${await getServiceToken()}`
},
body: JSON.stringify({ filter: event.body?.filter ?? {} }),
signal: AbortSignal.timeout(5000) // 5 second timeout - Node 24 feature
}
);
if (!upstreamResponse.ok) {
throw new Error(`Upstream error: ${upstreamResponse.status}`);
}
const products = await upstreamResponse.json();
return {
statusCode: 200,
headers: { "Content-Type": "application/json" },
body: JSON.stringify(products)
};
};
Lambda Response Streaming: Real-Time Output for LLM Workloads
A fifth capability worth covering — though slightly older (GA in late 2025 for API Gateway REST) — is Lambda Response Streaming enhancements. Lambda functions can now stream responses incrementally using a responseStream object in Node.js, supporting payloads up to 200 MB and delivering partial results to clients as they are produced.
The primary enterprise use case is LLM inference streaming. When invoking a large language model via Amazon Bedrock or a self-hosted model on Lambda Managed Instances, the model generates tokens progressively. Without streaming, the client waits for the entire response before receiving anything — a poor user experience for responses that take 5-30 seconds to generate. With response streaming, tokens are delivered to the client as they are generated, creating the familiar typewriter effect that users now expect from AI interfaces.
import { BedrockRuntimeClient, InvokeModelWithResponseStreamCommand } from "@aws-sdk/client-bedrock-runtime";
const bedrock = new BedrockRuntimeClient({ region: "us-east-1" });
// awslambda.streamifyResponse wraps the handler to enable streaming
export const handler = awslambda.streamifyResponse(async (event, responseStream, context) => {
const { prompt, tenantId } = JSON.parse(event.body);
// Write headers first (HTTP chunked transfer encoding)
const metadata = awslambda.HttpResponseStream.from(responseStream, {
statusCode: 200,
headers: {
"Content-Type": "text/event-stream",
"X-Tenant-ID": tenantId,
"Cache-Control": "no-cache"
}
});
const command = new InvokeModelWithResponseStreamCommand({
modelId: "anthropic.claude-3-5-sonnet-20241022-v2:0",
contentType: "application/json",
body: JSON.stringify({
messages: [{ role: "user", content: prompt }],
max_tokens: 2048,
anthropic_version: "bedrock-2023-05-31"
})
});
const response = await bedrock.send(command);
for await (const chunk of response.body) {
if (chunk.chunk?.bytes) {
const decoded = JSON.parse(Buffer.from(chunk.chunk.bytes).toString("utf-8"));
if (decoded.type === "content_block_delta" && decoded.delta?.text) {
// Stream token to client in real-time
metadata.write(`data: ${JSON.stringify({ token: decoded.delta.text })}
`);
}
}
}
metadata.end();
});
Enterprise Adoption Sequencing: Where to Start
flowchart TD
A["Assess Current Pain Points"] --> B{"Primary constraint?"}
B -->|"Queue scaling latency"| C["Week 1-2: SQS Provisioned Mode"]
B -->|"Multi-tenant SaaS security"| D["Week 1-2: Tenant Isolation Mode"]
B -->|"ML or GPU workloads"| E["Week 2-4: Lambda Managed Instances"]
B -->|"S3 claim-check pipelines"| F["Week 1: Migrate to 1MB payloads"]
C --> G["Week 3-4: Upgrade runtimes .NET 10 and Node.js 24"]
D --> G
E --> G
F --> G
G --> H["Week 5-6: Enable Lambda Durable Functions"]
H --> I["Month 2-3: Full 2026 stack review"]Unified Cost Optimisation: The 2026 Serverless Cost Stack
Running the full 2026 serverless stack gives you new levers for cost optimisation that did not exist 18 months ago. Here is a realistic cost comparison for a mid-scale enterprise SaaS processing 10 million API requests/month:
Compute (Lambda ARM64 Graviton3 vs. x86): ARM64 Lambda is 20% cheaper per GB-second and 15-40% faster. For a 10M request/month workload at 200ms average execution on 512 MB: ARM64 costs $10.30/month vs x86 $12.88/month. Annual saving: $30.96.
Queue processing (Standard ESM vs. Provisioned Mode): Provisioned Mode introduces poller costs (~$0.0001/poller-hour). 20 minimum pollers × 720 hours = $1.44/month. In exchange, you eliminate the 5-10 minute ramp penalty that forces over-provisioning of concurrency reserves. Most teams recover the poller cost through concurrency limit reductions.
S3 claim-check elimination: At 10M async events/month with an average 2 S3 API calls per event (put + get), you remove 20M S3 PUT/GET calls. At $0.0004/1000 GET + $0.005/1000 PUT: saving ~$108/month in S3 API costs, plus data transfer and storage for transient payloads.
The 2026 serverless stack is not just technically superior to 2023’s — it is measurably cheaper to operate at scale, especially after accounting for the engineering time previously spent building and maintaining workarounds.
Key Takeaways
- Lambda Managed Instances makes GPU and specialised compute accessible under the Lambda model — ideal for bursty ML inference, document processing, and high-CPU batch workloads with utilisation below ~40%
- SQS Provisioned Mode ESM eliminates the multi-minute burst scaling ramp — a critical fix for financial transaction processing, IoT pipelines, and any queue-driven workload with latency SLAs
- 1 MB async payloads across Lambda, SQS, and EventBridge obsoletes the S3 claim-check pattern for the majority of real-world event payloads, removing 2-3 S3 API calls per event and simplifying IAM and lifecycle management
- .NET 10 with Native AOT on ARM64 (Graviton3) achieves sub-50ms cold starts — a requalification moment for .NET teams that dismissed serverless due to cold start latency
- Lambda Response Streaming is the right mechanism for LLM inference endpoints — deliver tokens to clients in real time rather than blocking on full response generation
- Sequence adoption around your highest-pain constraint: scaling latency, tenant isolation, GPU access, or payload size. The features are independent and can be adopted incrementally
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.