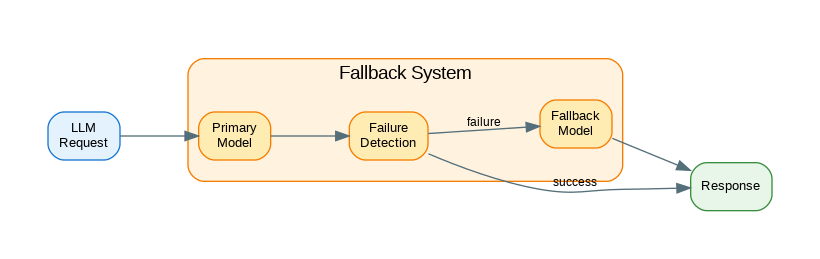
Introduction: Production LLM applications must handle failures gracefully—API outages, rate limits, timeouts, and degraded responses are inevitable. Fallback strategies ensure your application continues serving users when the primary model fails. This guide covers practical fallback patterns: multi-provider failover, graceful degradation, circuit breakers, retry policies, and health monitoring. The goal is building resilient systems that maintain availability even when individual components fail.
- Part 1 (this article): Multi-provider failover architecture
- Part 2: Building reliable AI applications
Resilience Architecture Overview
Building resilient LLM applications requires multiple layers of protection. This C4-style diagram shows how fallback strategies work together to ensure high availability.
flowchart TB
subgraph Client["Client Layer"]
REQ[Request]
end
subgraph Resilience["Resilience Layer"]
CB[Circuit Breaker]
RT[Retry Handler]
TO[Timeout Manager]
end
subgraph Routing["Provider Routing"]
LB[Load Balancer]
HC[Health Checker]
end
subgraph Primary["Primary Provider"]
P1[OpenAI GPT-4o]
end
subgraph Fallback["Fallback Providers"]
F1[Anthropic Claude]
F2[Azure OpenAI]
F3[Local Llama]
end
subgraph Cache["Degradation"]
SC[Cached Response]
GD[Graceful Error]
end
REQ --> CB
CB -->|Open| SC
CB -->|Closed| RT
RT --> TO
TO --> LB
HC --> LB
LB --> P1
P1 -.->|Fail| F1
F1 -.->|Fail| F2
F2 -.->|Fail| F3
F3 -.->|Fail| GD
style REQ fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style CB fill:#FCE4EC,stroke:#F48FB1,stroke-width:2px,color:#AD1457
style RT fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style TO fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style LB fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style HC fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style P1 fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style F1 fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style F2 fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style F3 fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style SC fill:#ECEFF1,stroke:#90A4AE,stroke-width:2px,color:#455A64
style GD fill:#ECEFF1,stroke:#90A4AE,stroke-width:2px,color:#455A64
Figure 1: C4 Container Diagram – LLM Resilience Architecture
Multi-Provider Failover
The following code implements multi-provider failover. Key aspects include proper error handling and clean separation of concerns.
from dataclasses import dataclass, field
from typing import Callable, Optional, Any
from datetime import datetime, timedelta
import asyncio
@dataclass
class Provider:
"""An LLM provider configuration."""
name: str
client: Any
model: str
priority: int = 0
max_retries: int = 3
timeout: float = 30.0
# Health tracking
is_healthy: bool = True
consecutive_failures: int = 0
last_failure: Optional[datetime] = None
failure_threshold: int = 3
recovery_time: timedelta = field(default_factory=lambda: timedelta(minutes=5))
def mark_failure(self):
"""Mark a failure for this provider."""
self.consecutive_failures += 1
self.last_failure = datetime.now()
if self.consecutive_failures >= self.failure_threshold:
self.is_healthy = False
def mark_success(self):
"""Mark a success for this provider."""
self.consecutive_failures = 0
self.is_healthy = True
def check_recovery(self) -> bool:
"""Check if provider should be retried after failure."""
if self.is_healthy:
return True
if self.last_failure is None:
return True
elapsed = datetime.now() - self.last_failure
if elapsed >= self.recovery_time:
# Reset for retry
self.consecutive_failures = 0
self.is_healthy = True
return True
return False
class MultiProviderClient:
"""Client with automatic failover across providers."""
def __init__(self, providers: list[Provider]):
self.providers = sorted(providers, key=lambda p: p.priority)
async def complete(
self,
messages: list[dict],
**kwargs
) -> dict:
"""Complete with automatic failover."""
errors = []
for provider in self.providers:
if not provider.check_recovery():
continue
try:
response = await self._call_provider(
provider,
messages,
**kwargs
)
provider.mark_success()
return {
"content": response,
"provider": provider.name,
"model": provider.model
}
except Exception as e:
provider.mark_failure()
errors.append({
"provider": provider.name,
"error": str(e)
})
continue
raise Exception(f"All providers failed: {errors}")
async def _call_provider(
self,
provider: Provider,
messages: list[dict],
**kwargs
) -> str:
"""Call a specific provider with timeout."""
async def call():
response = await provider.client.chat.completions.create(
model=provider.model,
messages=messages,
**kwargs
)
return response.choices[0].message.content
return await asyncio.wait_for(
call(),
timeout=provider.timeout
)
def get_health_status(self) -> list[dict]:
"""Get health status of all providers."""
return [
{
"name": p.name,
"model": p.model,
"is_healthy": p.is_healthy,
"consecutive_failures": p.consecutive_failures,
"last_failure": p.last_failure.isoformat() if p.last_failure else None
}
for p in self.providers
]
# Example setup
def create_multi_provider_client():
from openai import AsyncOpenAI
import anthropic
openai_client = AsyncOpenAI()
anthropic_client = anthropic.AsyncAnthropic()
providers = [
Provider(
name="openai",
client=openai_client,
model="gpt-4o",
priority=0
),
Provider(
name="anthropic",
client=anthropic_client,
model="claude-3-5-sonnet-20241022",
priority=1
),
Provider(
name="openai-fallback",
client=openai_client,
model="gpt-4o-mini",
priority=2
)
]
return MultiProviderClient(providers)Circuit Breaker Pattern
Circuit breakers prevent cascade failures by temporarily stopping requests to unhealthy providers. After a cooldown period, they test recovery before resuming full traffic.
from dataclasses import dataclass
from typing import Callable, Optional
from datetime import datetime, timedelta
from enum import Enum
import asyncio
class CircuitState(Enum):
CLOSED = "closed" # Normal operation
OPEN = "open" # Failing, reject requests
HALF_OPEN = "half_open" # Testing recovery
@dataclass
class CircuitBreaker:
"""Circuit breaker for LLM calls."""
name: str
failure_threshold: int = 5
recovery_timeout: timedelta = field(default_factory=lambda: timedelta(seconds=30))
half_open_max_calls: int = 3
state: CircuitState = CircuitState.CLOSED
failure_count: int = 0
success_count: int = 0
last_failure_time: Optional[datetime] = None
half_open_calls: int = 0
def can_execute(self) -> bool:
"""Check if request can proceed."""
if self.state == CircuitState.CLOSED:
return True
if self.state == CircuitState.OPEN:
# Check if recovery timeout has passed
if self._should_attempt_recovery():
self.state = CircuitState.HALF_OPEN
self.half_open_calls = 0
return True
return False
if self.state == CircuitState.HALF_OPEN:
# Allow limited calls in half-open state
return self.half_open_calls < self.half_open_max_calls
return False
def _should_attempt_recovery(self) -> bool:
"""Check if we should try recovery."""
if self.last_failure_time is None:
return True
elapsed = datetime.now() - self.last_failure_time
return elapsed >= self.recovery_timeout
def record_success(self):
"""Record successful call."""
if self.state == CircuitState.HALF_OPEN:
self.success_count += 1
if self.success_count >= self.half_open_max_calls:
# Recovery successful
self.state = CircuitState.CLOSED
self.failure_count = 0
self.success_count = 0
else:
self.failure_count = 0
def record_failure(self):
"""Record failed call."""
self.failure_count += 1
self.last_failure_time = datetime.now()
if self.state == CircuitState.HALF_OPEN:
# Recovery failed
self.state = CircuitState.OPEN
self.half_open_calls = 0
elif self.failure_count >= self.failure_threshold:
self.state = CircuitState.OPEN
class CircuitBreakerClient:
"""LLM client with circuit breaker."""
def __init__(
self,
client: Any,
circuit: CircuitBreaker,
fallback: Optional[Callable] = None
):
self.client = client
self.circuit = circuit
self.fallback = fallback
async def complete(
self,
messages: list[dict],
**kwargs
) -> str:
"""Complete with circuit breaker protection."""
if not self.circuit.can_execute():
if self.fallback:
return await self.fallback(messages, **kwargs)
raise Exception(f"Circuit {self.circuit.name} is open")
try:
if self.circuit.state == CircuitState.HALF_OPEN:
self.circuit.half_open_calls += 1
response = await self.client.chat.completions.create(
messages=messages,
**kwargs
)
self.circuit.record_success()
return response.choices[0].message.content
except Exception as e:
self.circuit.record_failure()
if self.fallback:
return await self.fallback(messages, **kwargs)
raise
# Multiple circuit breakers for different providers
class MultiCircuitClient:
"""Client with per-provider circuit breakers."""
def __init__(self):
self.circuits: dict[str, CircuitBreaker] = {}
self.clients: dict[str, Any] = {}
def add_provider(
self,
name: str,
client: Any,
failure_threshold: int = 5
):
"""Add a provider with its own circuit breaker."""
self.clients[name] = client
self.circuits[name] = CircuitBreaker(
name=name,
failure_threshold=failure_threshold
)
async def complete(
self,
messages: list[dict],
preferred_provider: str = None,
**kwargs
) -> dict:
"""Complete with automatic circuit breaker failover."""
# Try preferred provider first
if preferred_provider and preferred_provider in self.circuits:
circuit = self.circuits[preferred_provider]
if circuit.can_execute():
try:
client = self.clients[preferred_provider]
response = await client.chat.completions.create(
messages=messages,
**kwargs
)
circuit.record_success()
return {
"content": response.choices[0].message.content,
"provider": preferred_provider
}
except Exception:
circuit.record_failure()
# Try other providers
for name, circuit in self.circuits.items():
if name == preferred_provider:
continue
if not circuit.can_execute():
continue
try:
client = self.clients[name]
response = await client.chat.completions.create(
messages=messages,
**kwargs
)
circuit.record_success()
return {
"content": response.choices[0].message.content,
"provider": name
}
except Exception:
circuit.record_failure()
continue
raise Exception("All circuits are open")Retry Policies
Resilient systems gracefully handle failures through retry logic and fallback mechanisms. This implementation ensures reliability under adverse conditions.
from dataclasses import dataclass
from typing import Callable, Optional, Type
import asyncio
import random
@dataclass
class RetryPolicy:
"""Configuration for retry behavior."""
max_retries: int = 3
base_delay: float = 1.0
max_delay: float = 60.0
exponential_base: float = 2.0
jitter: bool = True
# Retryable exceptions
retryable_exceptions: tuple = (
Exception, # Customize based on provider
)
def get_delay(self, attempt: int) -> float:
"""Calculate delay for attempt number."""
delay = self.base_delay * (self.exponential_base ** attempt)
delay = min(delay, self.max_delay)
if self.jitter:
# Add random jitter (0.5x to 1.5x)
delay = delay * (0.5 + random.random())
return delay
def should_retry(self, exception: Exception, attempt: int) -> bool:
"""Check if we should retry this exception."""
if attempt >= self.max_retries:
return False
return isinstance(exception, self.retryable_exceptions)
class RetryingClient:
"""LLM client with configurable retry policy."""
def __init__(
self,
client: Any,
policy: RetryPolicy = None
):
self.client = client
self.policy = policy or RetryPolicy()
async def complete(
self,
messages: list[dict],
**kwargs
) -> str:
"""Complete with automatic retries."""
last_exception = None
for attempt in range(self.policy.max_retries + 1):
try:
response = await self.client.chat.completions.create(
messages=messages,
**kwargs
)
return response.choices[0].message.content
except Exception as e:
last_exception = e
if not self.policy.should_retry(e, attempt):
raise
delay = self.policy.get_delay(attempt)
await asyncio.sleep(delay)
raise last_exception
# Specialized retry policies
class RateLimitRetryPolicy(RetryPolicy):
"""Retry policy optimized for rate limits."""
def __init__(self):
super().__init__(
max_retries=5,
base_delay=5.0,
max_delay=120.0,
exponential_base=2.0,
jitter=True
)
def should_retry(self, exception: Exception, attempt: int) -> bool:
if attempt >= self.max_retries:
return False
# Check for rate limit errors
error_str = str(exception).lower()
return "rate limit" in error_str or "429" in error_str
class TimeoutRetryPolicy(RetryPolicy):
"""Retry policy for timeout errors."""
def __init__(self):
super().__init__(
max_retries=3,
base_delay=2.0,
max_delay=30.0,
exponential_base=1.5,
jitter=True
)
def should_retry(self, exception: Exception, attempt: int) -> bool:
if attempt >= self.max_retries:
return False
return isinstance(exception, (asyncio.TimeoutError, TimeoutError))
# Composite retry with multiple policies
class CompositeRetryPolicy:
"""Combine multiple retry policies."""
def __init__(self, policies: list[RetryPolicy]):
self.policies = policies
def should_retry(self, exception: Exception, attempt: int) -> bool:
"""Check if any policy allows retry."""
return any(
p.should_retry(exception, attempt)
for p in self.policies
)
def get_delay(self, attempt: int) -> float:
"""Get maximum delay from all policies."""
return max(p.get_delay(attempt) for p in self.policies)Graceful Degradation
The following code implements graceful degradation. Key aspects include proper error handling and clean separation of concerns.
from dataclasses import dataclass
from typing import Callable, Optional, Any
from enum import Enum
class DegradationLevel(Enum):
FULL = "full" # Full functionality
REDUCED = "reduced" # Reduced quality/features
MINIMAL = "minimal" # Basic functionality only
CACHED = "cached" # Cached responses only
OFFLINE = "offline" # Static fallback
@dataclass
class DegradationConfig:
"""Configuration for graceful degradation."""
level: DegradationLevel
model: Optional[str] = None
max_tokens: Optional[int] = None
temperature: Optional[float] = None
features_enabled: list[str] = None
@classmethod
def full(cls):
return cls(
level=DegradationLevel.FULL,
model="gpt-4o",
max_tokens=4096,
features_enabled=["streaming", "tools", "vision"]
)
@classmethod
def reduced(cls):
return cls(
level=DegradationLevel.REDUCED,
model="gpt-4o-mini",
max_tokens=2048,
features_enabled=["streaming"]
)
@classmethod
def minimal(cls):
return cls(
level=DegradationLevel.MINIMAL,
model="gpt-4o-mini",
max_tokens=512,
features_enabled=[]
)
class GracefulDegradationClient:
"""Client that degrades gracefully under pressure."""
def __init__(
self,
client: Any,
cache: Any = None
):
self.client = client
self.cache = cache
self.current_level = DegradationLevel.FULL
self.config = DegradationConfig.full()
def set_degradation_level(self, level: DegradationLevel):
"""Set current degradation level."""
self.current_level = level
if level == DegradationLevel.FULL:
self.config = DegradationConfig.full()
elif level == DegradationLevel.REDUCED:
self.config = DegradationConfig.reduced()
elif level == DegradationLevel.MINIMAL:
self.config = DegradationConfig.minimal()
async def complete(
self,
messages: list[dict],
**kwargs
) -> dict:
"""Complete with current degradation level."""
# Check cache first for cached/offline modes
if self.current_level in (DegradationLevel.CACHED, DegradationLevel.OFFLINE):
cached = await self._get_cached(messages)
if cached:
return {
"content": cached,
"degradation_level": self.current_level.value,
"from_cache": True
}
if self.current_level == DegradationLevel.OFFLINE:
return {
"content": self._get_offline_response(messages),
"degradation_level": self.current_level.value,
"from_cache": False
}
# Apply degradation config
request_kwargs = {**kwargs}
if self.config.model:
request_kwargs["model"] = self.config.model
if self.config.max_tokens:
request_kwargs["max_tokens"] = min(
kwargs.get("max_tokens", self.config.max_tokens),
self.config.max_tokens
)
# Remove disabled features
if "streaming" not in (self.config.features_enabled or []):
request_kwargs["stream"] = False
if "tools" not in (self.config.features_enabled or []):
request_kwargs.pop("tools", None)
try:
response = await self.client.chat.completions.create(
messages=messages,
**request_kwargs
)
content = response.choices[0].message.content
# Cache successful responses
if self.cache:
await self._cache_response(messages, content)
return {
"content": content,
"degradation_level": self.current_level.value,
"from_cache": False
}
except Exception as e:
# Auto-degrade on failure
if self.current_level == DegradationLevel.FULL:
self.set_degradation_level(DegradationLevel.REDUCED)
return await self.complete(messages, **kwargs)
elif self.current_level == DegradationLevel.REDUCED:
self.set_degradation_level(DegradationLevel.MINIMAL)
return await self.complete(messages, **kwargs)
elif self.current_level == DegradationLevel.MINIMAL:
self.set_degradation_level(DegradationLevel.CACHED)
return await self.complete(messages, **kwargs)
raise
async def _get_cached(self, messages: list[dict]) -> Optional[str]:
"""Get cached response."""
if not self.cache:
return None
key = self._cache_key(messages)
return await self.cache.get(key)
async def _cache_response(self, messages: list[dict], response: str):
"""Cache a response."""
if not self.cache:
return
key = self._cache_key(messages)
await self.cache.set(key, response)
def _cache_key(self, messages: list[dict]) -> str:
"""Generate cache key from messages."""
import hashlib
content = str(messages)
return hashlib.md5(content.encode()).hexdigest()
def _get_offline_response(self, messages: list[dict]) -> str:
"""Get static offline response."""
return "I'm currently operating in offline mode. Please try again later."Production Fallback Service
The following implementation demonstrates a production-ready approach to production fallback service. This code includes proper error handling, logging, and configuration management.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional
import asyncio
app = FastAPI()
# Initialize components
multi_provider = create_multi_provider_client()
circuit_client = MultiCircuitClient()
degradation_client = None # Initialize with actual client
class CompletionRequest(BaseModel):
messages: list[dict]
model: Optional[str] = None
max_tokens: Optional[int] = None
temperature: Optional[float] = 0.7
preferred_provider: Optional[str] = None
class HealthResponse(BaseModel):
status: str
providers: list[dict]
@app.post("/v1/completions")
async def create_completion(request: CompletionRequest):
"""Create completion with automatic failover."""
try:
result = await multi_provider.complete(
messages=request.messages,
max_tokens=request.max_tokens,
temperature=request.temperature
)
return {
"content": result["content"],
"provider": result["provider"],
"model": result["model"]
}
except Exception as e:
raise HTTPException(503, f"All providers unavailable: {str(e)}")
@app.post("/v1/completions/circuit")
async def create_completion_circuit(request: CompletionRequest):
"""Create completion with circuit breaker protection."""
try:
result = await circuit_client.complete(
messages=request.messages,
preferred_provider=request.preferred_provider,
max_tokens=request.max_tokens,
temperature=request.temperature
)
return result
except Exception as e:
raise HTTPException(503, str(e))
@app.get("/v1/health")
async def health_check() -> HealthResponse:
"""Get health status of all providers."""
return HealthResponse(
status="healthy",
providers=multi_provider.get_health_status()
)
@app.post("/v1/degradation/level")
async def set_degradation_level(level: str):
"""Manually set degradation level."""
try:
degradation_level = DegradationLevel(level)
degradation_client.set_degradation_level(degradation_level)
return {"level": level, "status": "updated"}
except ValueError:
raise HTTPException(400, f"Invalid level: {level}")
@app.get("/v1/circuits")
async def get_circuit_status():
"""Get status of all circuit breakers."""
return {
name: {
"state": circuit.state.value,
"failure_count": circuit.failure_count,
"last_failure": circuit.last_failure_time.isoformat() if circuit.last_failure_time else None
}
for name, circuit in circuit_client.circuits.items()
}References
- Circuit Breaker Pattern: https://martinfowler.com/bliki/CircuitBreaker.html
- Retry Patterns: https://docs.microsoft.com/en-us/azure/architecture/patterns/retry
- Tenacity Library: https://tenacity.readthedocs.io/
- OpenAI Error Handling: https://platform.openai.com/docs/guides/error-codes
Conclusion
Fallback strategies are essential for production LLM applications. Multi-provider failover ensures availability when any single provider fails—configure multiple providers with priority ordering and automatic health tracking. Circuit breakers prevent cascade failures by temporarily blocking requests to failing services. Implement exponential backoff with jitter for retries to avoid thundering herd problems. Graceful degradation maintains user experience by progressively reducing functionality rather than failing completely. Monitor provider health continuously and alert on degradation. The goal is building systems that bend but don’t break—users should experience reduced quality before complete failure.
Key Takeaways
- ✅ Always have fallbacks – Single-provider dependency is a production risk
- ✅ Implement circuit breakers – Prevent cascade failures when providers degrade
- ✅ Cache aggressively – Cached responses work when all providers fail
- ✅ Test failover regularly – Untested fallbacks fail when you need them
- ✅ Monitor provider health – Proactive detection beats reactive recovery
Conclusion
Resilient LLM applications require thoughtful fallback strategies. By implementing multi-provider failover, circuit breakers, and graceful degradation, you can build systems that maintain availability even when individual providers experience outages.
References
- Circuit Breaker Pattern – Martin Fowler
- AWS: Using Load Shedding to Avoid Overload
- LLM Reliability Patterns
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.