Introduction: Observability is essential for production LLM applications—you need visibility into latency, token usage, costs, error rates, and output quality. Unlike traditional applications where you can rely on status codes and response times, LLM applications require tracking prompt versions, model behavior, and semantic quality metrics. This guide covers practical observability: distributed tracing for multi-step LLM workflows, metrics collection for dashboards and alerts, structured logging for debugging, and integration with observability platforms like LangSmith, Langfuse, and OpenTelemetry.
- Part 1 (this article): Tracing, metrics, and logging fundamentals
- Part 2: Cost tracking and quality monitoring
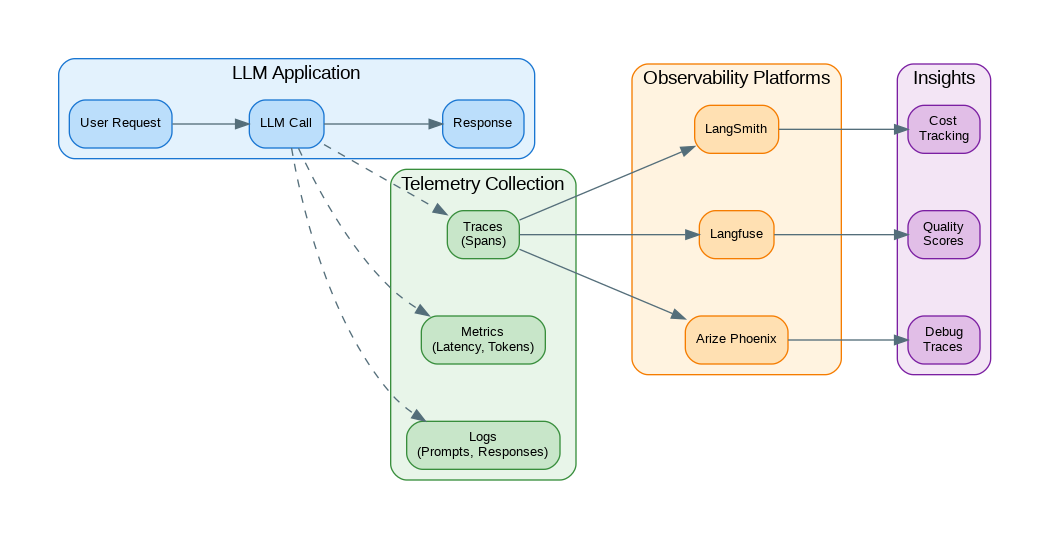
Observability Architecture
Comprehensive observability for LLM applications requires tracing, metrics, and logging working together. This diagram shows how observability components integrate into the system.
flowchart TB
subgraph App["Application Layer"]
API[API Endpoint]
LLM[LLM Client]
VDB[Vector Search]
end
subgraph Instrumentation["Instrumentation"]
TR[Trace Context]
SP[Span Processor]
MT[Metric Collector]
end
subgraph Export["Exporters"]
OT[OTLP Exporter]
LF[Langfuse Client]
LS[LangSmith Client]
end
subgraph Backend["Observability Backend"]
JA[Jaeger/Tempo]
PR[Prometheus]
GR[Grafana]
LFB[Langfuse]
end
API --> TR
LLM --> TR
VDB --> TR
TR --> SP
SP --> MT
MT --> OT
MT --> LF
MT --> LS
OT --> JA
OT --> PR
JA --> GR
PR --> GR
LF --> LFB
style API fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style LLM fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style VDB fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style TR fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style SP fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style MT fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style OT fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style LF fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style LS fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style JA fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style PR fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style GR fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style LFB fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
Figure 1: C4 Container Diagram – LLM Observability Architecture
Distributed Tracing
The following code implements distributed tracing. Key aspects include proper error handling and clean separation of concerns.
import uuid
import time
from dataclasses import dataclass, field
from typing import Optional, Any
from datetime import datetime
from contextlib import contextmanager
@dataclass
class Span:
"""A single span in a trace."""
span_id: str
name: str
trace_id: str
parent_id: Optional[str] = None
start_time: float = field(default_factory=time.time)
end_time: Optional[float] = None
attributes: dict = field(default_factory=dict)
events: list = field(default_factory=list)
status: str = "ok"
def set_attribute(self, key: str, value: Any):
self.attributes[key] = value
def add_event(self, name: str, attributes: dict = None):
self.events.append({
"name": name,
"timestamp": time.time(),
"attributes": attributes or {}
})
def end(self, status: str = "ok"):
self.end_time = time.time()
self.status = status
@property
def duration_ms(self) -> float:
if self.end_time:
return (self.end_time - self.start_time) * 1000
return 0
class Tracer:
"""Simple tracer for LLM operations."""
def __init__(self):
self.spans: dict[str, list[Span]] = {}
self.current_trace_id: Optional[str] = None
self.current_span_id: Optional[str] = None
@contextmanager
def start_trace(self, name: str):
"""Start a new trace."""
trace_id = str(uuid.uuid4())
self.current_trace_id = trace_id
self.spans[trace_id] = []
with self.start_span(name) as span:
yield span
self.current_trace_id = None
@contextmanager
def start_span(self, name: str):
"""Start a new span within current trace."""
span = Span(
span_id=str(uuid.uuid4()),
name=name,
trace_id=self.current_trace_id,
parent_id=self.current_span_id
)
self.spans[self.current_trace_id].append(span)
old_span_id = self.current_span_id
self.current_span_id = span.span_id
try:
yield span
span.end("ok")
except Exception as e:
span.set_attribute("error", str(e))
span.end("error")
raise
finally:
self.current_span_id = old_span_id
def get_trace(self, trace_id: str) -> list[Span]:
return self.spans.get(trace_id, [])
# LLM-specific tracer
class LLMTracer(Tracer):
"""Tracer with LLM-specific instrumentation."""
@contextmanager
def trace_llm_call(
self,
model: str,
prompt: str,
**kwargs
):
"""Trace an LLM API call."""
with self.start_span(f"llm.{model}") as span:
span.set_attribute("llm.model", model)
span.set_attribute("llm.prompt_length", len(prompt))
span.set_attribute("llm.prompt_preview", prompt[:200])
for key, value in kwargs.items():
span.set_attribute(f"llm.{key}", value)
span.add_event("request_sent")
yield span
@contextmanager
def trace_retrieval(self, query: str, top_k: int = 5):
"""Trace a retrieval operation."""
with self.start_span("retrieval") as span:
span.set_attribute("retrieval.query", query)
span.set_attribute("retrieval.top_k", top_k)
yield span
@contextmanager
def trace_chain(self, chain_name: str):
"""Trace a chain of operations."""
with self.start_span(f"chain.{chain_name}") as span:
yield span
# Usage
tracer = LLMTracer()
def rag_query(question: str) -> str:
"""RAG query with full tracing."""
with tracer.start_trace("rag_query") as trace:
trace.set_attribute("user.question", question)
# Retrieval
with tracer.trace_retrieval(question, top_k=5) as retrieval_span:
# Simulate retrieval
docs = ["doc1", "doc2", "doc3"]
retrieval_span.set_attribute("retrieval.doc_count", len(docs))
# LLM call
with tracer.trace_llm_call(
model="gpt-4o-mini",
prompt=f"Answer based on: {docs}\n\nQuestion: {question}"
) as llm_span:
# Simulate LLM call
response = "This is the answer"
llm_span.set_attribute("llm.response_length", len(response))
llm_span.set_attribute("llm.tokens_used", 150)
return responseMetrics Collection
Monitoring provides visibility into system behavior. The following code instruments key metrics for observability.
from dataclasses import dataclass
from collections import defaultdict
from typing import Callable
import statistics
@dataclass
class MetricValue:
"""A single metric measurement."""
name: str
value: float
timestamp: float
labels: dict = field(default_factory=dict)
class MetricsCollector:
"""Collect and aggregate metrics."""
def __init__(self):
self.metrics: dict[str, list[MetricValue]] = defaultdict(list)
self.counters: dict[str, float] = defaultdict(float)
self.gauges: dict[str, float] = {}
def record(self, name: str, value: float, labels: dict = None):
"""Record a metric value."""
metric = MetricValue(
name=name,
value=value,
timestamp=time.time(),
labels=labels or {}
)
self.metrics[name].append(metric)
def increment(self, name: str, value: float = 1, labels: dict = None):
"""Increment a counter."""
key = f"{name}:{labels}" if labels else name
self.counters[key] += value
def set_gauge(self, name: str, value: float, labels: dict = None):
"""Set a gauge value."""
key = f"{name}:{labels}" if labels else name
self.gauges[key] = value
def get_stats(self, name: str) -> dict:
"""Get statistics for a metric."""
values = [m.value for m in self.metrics.get(name, [])]
if not values:
return {}
return {
"count": len(values),
"sum": sum(values),
"mean": statistics.mean(values),
"median": statistics.median(values),
"min": min(values),
"max": max(values),
"p95": self._percentile(values, 95),
"p99": self._percentile(values, 99)
}
def _percentile(self, values: list[float], p: int) -> float:
"""Calculate percentile."""
sorted_values = sorted(values)
idx = int(len(sorted_values) * p / 100)
return sorted_values[min(idx, len(sorted_values) - 1)]
class LLMMetrics:
"""LLM-specific metrics."""
def __init__(self):
self.collector = MetricsCollector()
def record_request(
self,
model: str,
latency_ms: float,
input_tokens: int,
output_tokens: int,
success: bool
):
"""Record LLM request metrics."""
labels = {"model": model}
self.collector.record("llm.latency_ms", latency_ms, labels)
self.collector.record("llm.input_tokens", input_tokens, labels)
self.collector.record("llm.output_tokens", output_tokens, labels)
self.collector.increment("llm.requests_total", labels=labels)
if success:
self.collector.increment("llm.requests_success", labels=labels)
else:
self.collector.increment("llm.requests_failed", labels=labels)
def record_cost(self, model: str, cost: float):
"""Record cost metrics."""
self.collector.increment(
"llm.cost_total",
value=cost,
labels={"model": model}
)
def record_cache_hit(self, hit: bool):
"""Record cache metrics."""
if hit:
self.collector.increment("llm.cache_hits")
else:
self.collector.increment("llm.cache_misses")
def get_dashboard_data(self) -> dict:
"""Get data for dashboard."""
return {
"latency": self.collector.get_stats("llm.latency_ms"),
"tokens": {
"input": self.collector.get_stats("llm.input_tokens"),
"output": self.collector.get_stats("llm.output_tokens")
},
"requests": {
"total": self.collector.counters.get("llm.requests_total", 0),
"success": self.collector.counters.get("llm.requests_success", 0),
"failed": self.collector.counters.get("llm.requests_failed", 0)
},
"cost": self.collector.counters.get("llm.cost_total", 0)
}
# Usage
metrics = LLMMetrics()
# Record some requests
metrics.record_request("gpt-4o-mini", 450, 100, 200, True)
metrics.record_request("gpt-4o-mini", 520, 150, 180, True)
metrics.record_request("gpt-4o-mini", 1200, 200, 50, False)
metrics.record_cost("gpt-4o-mini", 0.0005)
print(metrics.get_dashboard_data())Structured Logging
The following code implements structured logging. Key aspects include proper error handling and clean separation of concerns.
import json
import logging
from typing import Any
from functools import wraps
class StructuredLogger:
"""Structured JSON logging for LLM operations."""
def __init__(self, name: str = "llm"):
self.logger = logging.getLogger(name)
self.logger.setLevel(logging.INFO)
# JSON formatter
handler = logging.StreamHandler()
handler.setFormatter(self._json_formatter())
self.logger.addHandler(handler)
self.context: dict = {}
def _json_formatter(self):
"""Create JSON log formatter."""
class JSONFormatter(logging.Formatter):
def format(self, record):
log_data = {
"timestamp": datetime.utcnow().isoformat(),
"level": record.levelname,
"message": record.getMessage(),
"logger": record.name
}
if hasattr(record, "extra"):
log_data.update(record.extra)
return json.dumps(log_data)
return JSONFormatter()
def set_context(self, **kwargs):
"""Set context that will be included in all logs."""
self.context.update(kwargs)
def clear_context(self):
"""Clear logging context."""
self.context = {}
def _log(self, level: int, message: str, **kwargs):
"""Log with structured data."""
extra = {**self.context, **kwargs}
self.logger.log(level, message, extra={"extra": extra})
def info(self, message: str, **kwargs):
self._log(logging.INFO, message, **kwargs)
def warning(self, message: str, **kwargs):
self._log(logging.WARNING, message, **kwargs)
def error(self, message: str, **kwargs):
self._log(logging.ERROR, message, **kwargs)
def log_llm_request(
self,
model: str,
prompt: str,
response: str,
latency_ms: float,
tokens: dict
):
"""Log LLM request with full details."""
self.info(
"LLM request completed",
event="llm_request",
model=model,
prompt_preview=prompt[:200],
prompt_length=len(prompt),
response_preview=response[:200],
response_length=len(response),
latency_ms=latency_ms,
input_tokens=tokens.get("input", 0),
output_tokens=tokens.get("output", 0)
)
def log_error(self, error: Exception, context: dict = None):
"""Log error with context."""
self.error(
f"Error: {str(error)}",
event="error",
error_type=type(error).__name__,
error_message=str(error),
**(context or {})
)
# Decorator for automatic logging
def log_llm_call(logger: StructuredLogger):
"""Decorator to log LLM calls."""
def decorator(func: Callable):
@wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
try:
result = func(*args, **kwargs)
latency = (time.time() - start) * 1000
logger.info(
f"{func.__name__} completed",
event="function_call",
function=func.__name__,
latency_ms=latency,
success=True
)
return result
except Exception as e:
latency = (time.time() - start) * 1000
logger.error(
f"{func.__name__} failed",
event="function_call",
function=func.__name__,
latency_ms=latency,
success=False,
error=str(e)
)
raise
return wrapper
return decorator
# Usage
logger = StructuredLogger("my_app")
logger.set_context(service="rag-api", environment="production")
@log_llm_call(logger)
def process_query(query: str) -> str:
# Process query
return "result"OpenTelemetry Integration
The following code implements opentelemetry integration. Key aspects include proper error handling and clean separation of concerns.
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.requests import RequestsInstrumentor
from contextlib import contextmanager
# Setup OpenTelemetry
def setup_otel(service_name: str, otlp_endpoint: str = None):
"""Setup OpenTelemetry tracing."""
provider = TracerProvider()
if otlp_endpoint:
exporter = OTLPSpanExporter(endpoint=otlp_endpoint)
provider.add_span_processor(BatchSpanProcessor(exporter))
trace.set_tracer_provider(provider)
# Auto-instrument HTTP requests
RequestsInstrumentor().instrument()
return trace.get_tracer(service_name)
class OTelLLMTracer:
"""OpenTelemetry-based LLM tracer."""
def __init__(self, service_name: str = "llm-service"):
self.tracer = trace.get_tracer(service_name)
@contextmanager
def trace_llm_call(
self,
model: str,
operation: str = "completion"
):
"""Trace LLM call with OpenTelemetry."""
with self.tracer.start_as_current_span(
f"llm.{operation}",
kind=trace.SpanKind.CLIENT
) as span:
span.set_attribute("llm.model", model)
span.set_attribute("llm.operation", operation)
try:
yield span
except Exception as e:
span.set_status(trace.Status(trace.StatusCode.ERROR, str(e)))
span.record_exception(e)
raise
def record_tokens(self, span, input_tokens: int, output_tokens: int):
"""Record token usage on span."""
span.set_attribute("llm.input_tokens", input_tokens)
span.set_attribute("llm.output_tokens", output_tokens)
span.set_attribute("llm.total_tokens", input_tokens + output_tokens)
def record_cost(self, span, cost: float):
"""Record cost on span."""
span.set_attribute("llm.cost_usd", cost)
# Instrumented LLM client
class InstrumentedLLMClient:
"""LLM client with OpenTelemetry instrumentation."""
def __init__(self, tracer: OTelLLMTracer = None):
from openai import OpenAI
self.client = OpenAI()
self.tracer = tracer or OTelLLMTracer()
def complete(self, prompt: str, model: str = "gpt-4o-mini") -> str:
"""Complete with tracing."""
with self.tracer.trace_llm_call(model, "completion") as span:
span.set_attribute("llm.prompt_length", len(prompt))
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
self.tracer.record_tokens(
span,
response.usage.prompt_tokens,
response.usage.completion_tokens
)
span.set_attribute("llm.response_length", len(result))
return resultLangfuse Integration
Langfuse provides specialized LLM observability with automatic prompt/response logging, cost tracking, and quality metrics. The following integration captures detailed traces of every LLM interaction.
from langfuse import Langfuse
from langfuse.decorators import observe, langfuse_context
# Initialize Langfuse
langfuse = Langfuse(
public_key="pk-...",
secret_key="sk-...",
host="https://cloud.langfuse.com"
)
class LangfuseTracer:
"""Langfuse-based tracing for LLM applications."""
def __init__(self):
self.langfuse = langfuse
def trace_generation(
self,
name: str,
model: str,
prompt: str,
completion: str,
usage: dict = None,
metadata: dict = None
):
"""Log a generation to Langfuse."""
trace = self.langfuse.trace(name=name)
trace.generation(
name=f"{name}_generation",
model=model,
input=prompt,
output=completion,
usage=usage,
metadata=metadata
)
return trace
def score_generation(
self,
trace_id: str,
name: str,
value: float,
comment: str = None
):
"""Add a score to a generation."""
self.langfuse.score(
trace_id=trace_id,
name=name,
value=value,
comment=comment
)
# Using decorators
@observe()
def rag_pipeline(question: str) -> str:
"""RAG pipeline with automatic Langfuse tracing."""
# Retrieval step
docs = retrieve_documents(question)
# Generation step
answer = generate_answer(question, docs)
return answer
@observe(as_type="generation")
def generate_answer(question: str, context: list[str]) -> str:
"""Generate answer with Langfuse generation tracking."""
from openai import OpenAI
client = OpenAI()
prompt = f"Context: {context}\n\nQuestion: {question}"
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}]
)
# Update observation with usage
langfuse_context.update_current_observation(
usage={
"input": response.usage.prompt_tokens,
"output": response.usage.completion_tokens
}
)
return response.choices[0].message.content
@observe(as_type="span")
def retrieve_documents(query: str) -> list[str]:
"""Retrieve documents with span tracking."""
# Simulate retrieval
docs = ["doc1", "doc2", "doc3"]
langfuse_context.update_current_observation(
metadata={"doc_count": len(docs)}
)
return docsProduction Observability Service
The following implementation demonstrates a production-ready approach to production observability service. This code includes proper error handling, logging, and configuration management.
from fastapi import FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
import time
app = FastAPI()
# Initialize observability components
tracer = LLMTracer()
metrics = LLMMetrics()
logger = StructuredLogger("llm-api")
# Middleware for request tracing
@app.middleware("http")
async def trace_requests(request: Request, call_next):
"""Trace all HTTP requests."""
request_id = str(uuid.uuid4())
start_time = time.time()
logger.set_context(request_id=request_id)
try:
response = await call_next(request)
latency = (time.time() - start_time) * 1000
logger.info(
"Request completed",
event="http_request",
method=request.method,
path=request.url.path,
status_code=response.status_code,
latency_ms=latency
)
return response
except Exception as e:
logger.log_error(e, {"path": request.url.path})
raise
finally:
logger.clear_context()
@app.post("/complete")
async def complete(prompt: str, model: str = "gpt-4o-mini"):
"""Completion endpoint with full observability."""
with tracer.start_trace("completion") as trace:
start = time.time()
try:
with tracer.trace_llm_call(model, prompt) as span:
# Call LLM
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
# Record metrics
latency = (time.time() - start) * 1000
span.set_attribute("llm.response_length", len(result))
span.set_attribute("llm.latency_ms", latency)
metrics.record_request(
model=model,
latency_ms=latency,
input_tokens=response.usage.prompt_tokens,
output_tokens=response.usage.completion_tokens,
success=True
)
logger.log_llm_request(
model=model,
prompt=prompt,
response=result,
latency_ms=latency,
tokens={
"input": response.usage.prompt_tokens,
"output": response.usage.completion_tokens
}
)
return {"response": result, "model": model}
except Exception as e:
metrics.record_request(
model=model,
latency_ms=(time.time() - start) * 1000,
input_tokens=0,
output_tokens=0,
success=False
)
raise
@app.get("/metrics")
async def get_metrics():
"""Get current metrics."""
return metrics.get_dashboard_data()
@app.get("/health")
async def health():
"""Health check with metrics summary."""
dashboard = metrics.get_dashboard_data()
return {
"status": "healthy",
"requests_total": dashboard["requests"]["total"],
"error_rate": (
dashboard["requests"]["failed"] /
max(dashboard["requests"]["total"], 1)
),
"avg_latency_ms": dashboard["latency"].get("mean", 0)
}References
- Langfuse: https://langfuse.com/docs
- LangSmith: https://docs.smith.langchain.com/
- OpenTelemetry Python: https://opentelemetry.io/docs/languages/python/
- Weights & Biases Prompts: https://docs.wandb.ai/guides/prompts
Conclusion
Observability is non-negotiable for production LLM applications. Implement distributed tracing to understand multi-step workflows and identify bottlenecks. Collect metrics for latency, token usage, costs, and error rates—set alerts on anomalies. Use structured logging with JSON format for easy querying and debugging. Consider purpose-built LLM observability platforms like Langfuse or LangSmith that understand LLM-specific concepts like prompts, completions, and token usage. For enterprise environments, integrate with OpenTelemetry to leverage existing observability infrastructure. The goal is complete visibility into your LLM application’s behavior, performance, and costs.
Key Takeaways
- ✅ Trace every request – Full observability into LLM call chains
- ✅ Track costs per feature – Know where budget goes
- ✅ Monitor quality metrics – Catch degradation before users complain
- ✅ Log prompts and responses – Essential for debugging and improvement
- ✅ Set up alerts – Proactive notification of anomalies
Conclusion
Effective observability transforms LLM development from guesswork to data-driven iteration. With comprehensive tracing, metrics, and quality monitoring, you can optimize costs, improve quality, and debug issues rapidly.
References
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.